Using images to develop software has proven very useful. However an image may break for multiple reasons and not being able to open anymore. For example when using a breakpoint in a method used by the system may prevent it to open. We explain here how we were able to recover such an image.
Have you ever had a Pharo image that does not open anymore ? Hours or even days of work lost forever because you forgot to save your code outside of the image ? It happens to all Pharo developers at some point. And we all hate the existing solutions when a lot of code is involved.
Epicea:
Epicea is pretty much the best option we have. Quite frankly, it saved me multiple times. It is awesome in a number of cases, because it allows us to reapply the latest changes on the current image. One image may be dead, but we are able to resurrect it ! However Epicea is not as great when you have to apply back multiple sessions, ones that you forgot, and particularly when it touches sensitive code such as the Compiler.
Real World Case Description
The Murder
In the RMOD team, we currently have a student that is working on having multiple OS windows, rather than only one. While working on this project, she was modifying very sensitive user interface code. At some point, she added a breakpoint to explore a method, and saved her image to be sure she would be able to recover if something went wrong. She then closed the image. This image still had the breakpoint in the method.
Later, she tries to open the image.\newline Nothing. The Pharo Launcher stays silent.
The Investigation
We followed advice from a colleague.
“If you can run images on your laptop but not from Pharo Launcher, I suggest you open Pharo Launcher, select an image you know it can be opened, right-click on it and click on ‘copy launch command’. You will get the command PL use to run the image. Then you could try it directly from a shell and see what happens. It is often the best way to understand what is wrong when an image does not open.”
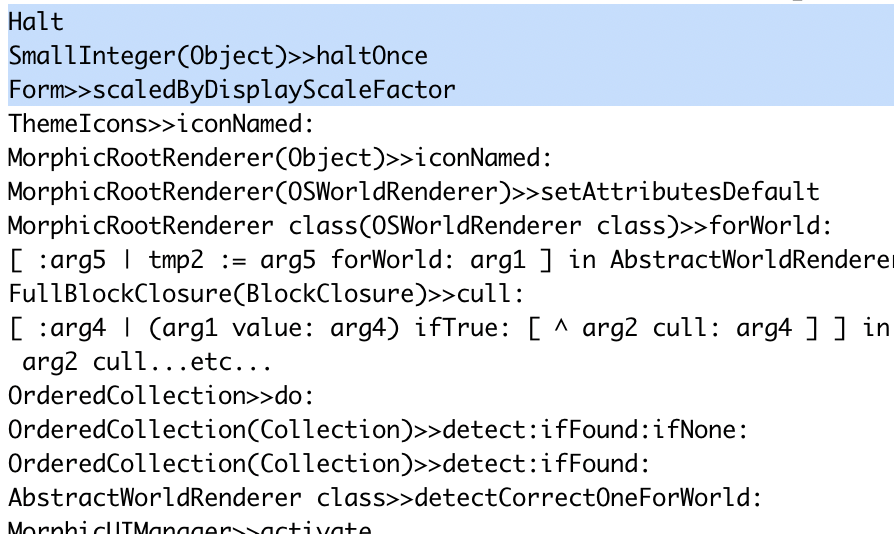
Following his advice, we found that the breakpoint is triggered by the startup of his image. Therefore, the image cannot open the UI. Therefore, the image cannot open.
Debug stack printed by the VM when trying to open the image from a command line. This clearly shows that (1) the error preventing to open is indeed the halt and (2) the method containing the halt.
The Resurrection
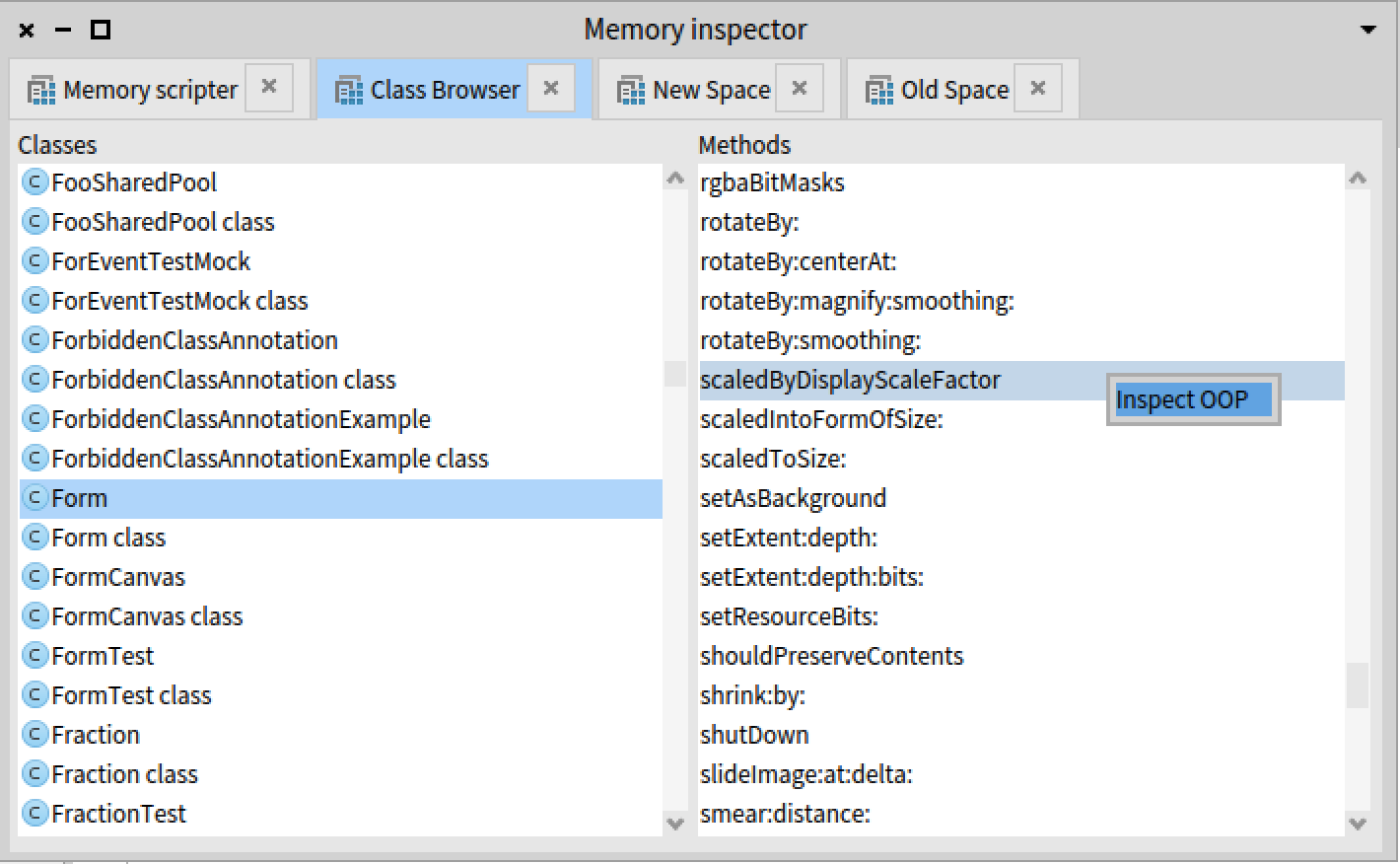
To fix this, we used a recent tool we wrote based on the VM simulator: Polyphemus (https://github.com/hogoww/Polyphemus/). We opened the dead image inside a VM simulator, running inside a clean Pharo image. We then explored the classes to find the class with the breakpoint method.
Allows to browse the classes and methods of the dead image. This allows to bypass the metacircularity of the environment and to browse the methods without executing any of them.
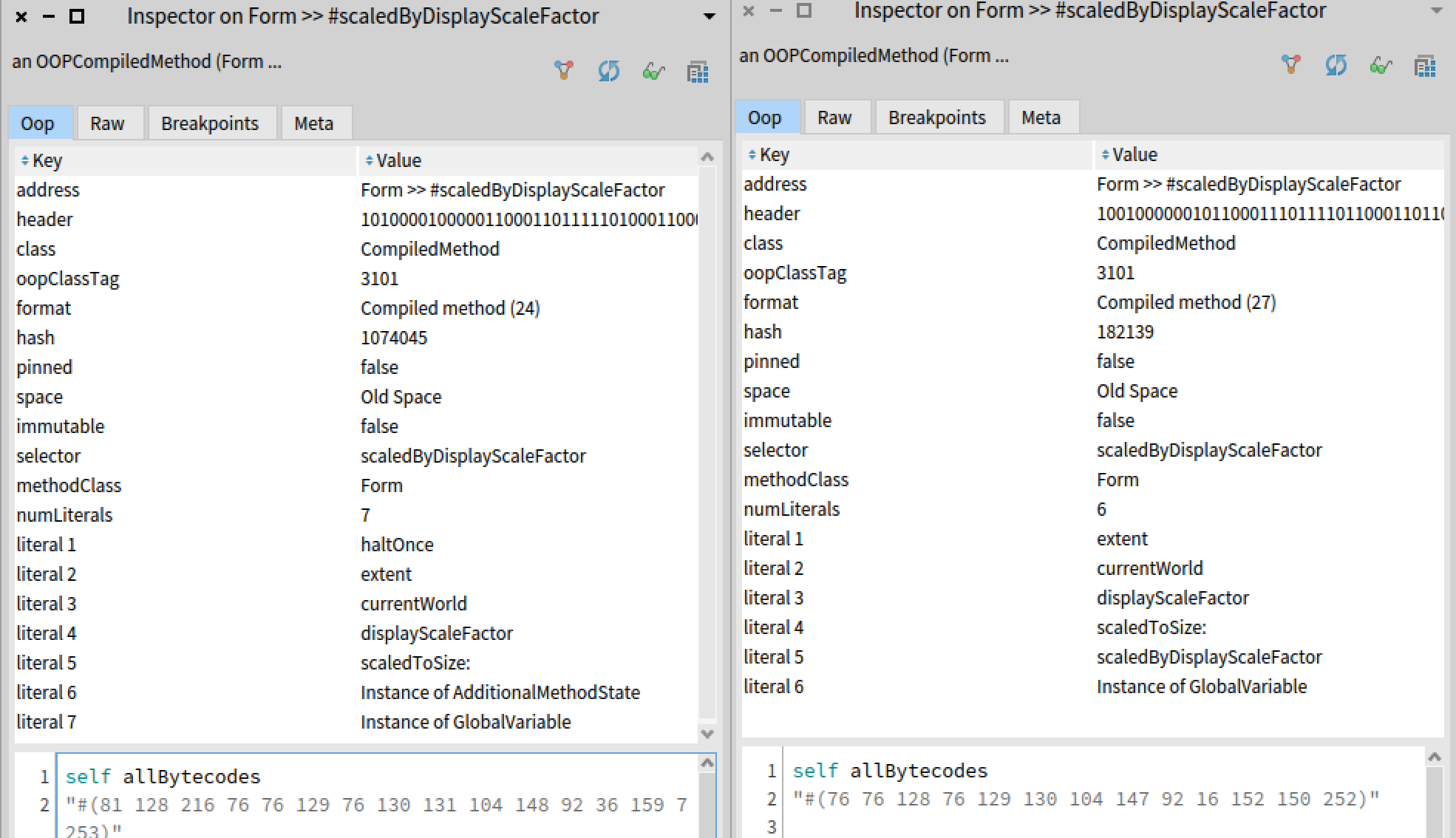
Once we had the method object, we were able to compare the breakpoint version of this method, with one from a fresh Pharo 11, and analyse what we had to fix.
Inspection of the breakpoint compiled method object on the left and the clean compiled method object on the right. The breakpoint method has 3 more bytecodes sending the haltOnce message. It also has an extra literal for the selector \textit{#haltOnce} in the first literal.
Of course, we first had to change the bytecodes. We take the bytecode from the Pharo version and inject it into the image. We replaced manually the content of this object with bytecodes that would execute the correct behavior. We replaced the last extra bytecodes with 0.
This also required fixing the method literals, which are used to express the breakpoint. To send a message, the bytecode pushes the selector of that message on the execution stack. To have this selector available, it is stored inside the method literals. In this case, we can see that the \textit{haltOnce} selector is stored at index one. Therefore, the literals were off by one, and the indexes used by the bytecodes were wrong. To fix that, we replace each literal by the next one. This leaves a duplicated literal in the last index. This is not really a problem, because it is not used in the bytecode. This could be a problem because the last and penultimate literals have particular properties. They hold the class and the selector of the method. Therefore we advised the student to immediately recompile the method for safety !
With the abstractions provided by Polyphemus, it took us less than an hour to fix this image and recover days of work.
Note that this solution was possible because the method with the breakpoint has both more bytecodes and literals than the clean one. Therefore we were able to keep it simple and just patch it. More complex solutions would be required for more complex cases.
Closing Words
Although rudimentary, these solutions were achievable because of the initial effort of reifying the objects inside the VM simulator. We are also investigating how to investigate and repair images suffering from memory corruption. At this time, Polyphemus is just a base. A base that took a lot of thinking and effort to create, but a base nonetheless. The tools are yet to come ! https://github.com/hogoww/Polyphemus/
Data visualization is the discipline of trying to understand data information by placing it in a visual context so that patterns and trends that might not be detected easily will appear.
In this article I will describe step by step how to create a visualization using Roassal30 in a beginner friendly way. In addition we will show how we can turn a script in a visualization class with powerful customization hooks. Finally we will show how we can extend the object inspector with a new dedicated visualization. Doing so we show (1) how specific domains can be represented differently and specifically and (2) how domain objects can be navigated using diverse representations (lists, table, visualization).
Who is this article for?
The audience of this article:
Data scientists – readers familiar with Pharo.
Designers of visualization engines will find valuable resources regarding the design and implementation of a visualization engine.
Getting started with Roassal30
Roassal is a visualization engine developed in Pharo (http://pharo.org). Roassal offers a simple API. It shares similarities of other visualization engines like Mathplotlib and D3.js. Roassal3.0 produces naturally interactive visualizations to directly explore and operate on the represented domain object (https://link.springer.com/book/10.1007/978-1-4842-7161-2). Roassal 2’s documentation is available at (http://agilevisualization.com).
To use, it download the lasted stable version, currently Pharo10. Roassal3.0 is integrated in the Pharo environment, now if you want to use the last version of Roassal, select the menu item
Library >> Roassal3 >> Load full version
Loading Roassal should take a few seconds, depending on your Internet connection.
Visualizing a class hierarchy
Roassal provides examples as scripts directly executable in the Playground. We will start by designing a new visualization as a large script and in the following section we will turn into a class.
The following example, display the full hierarchy of a class with shapes whose size and colors depend on the class they represent. Evaluate the following example with Cmd+D
data := Collection withAllSubclasses.
boxes := data collect: [ :class |
RSBox new
model: class;
popup;
draggable;
yourself ].
canvas := RSCanvas new.
canvas addAll: boxes.
RSNormalizer size
from: 10;
to: 100;
shapes: boxes;
normalize: #linesOfCode.
RSNormalizer color
from: Color blue;
to: Color red;
shapes: boxes;
normalize: #linesOfCode.
RSLineBuilder orthoVertical
withVerticalAttachPoint;
shapes: boxes;
connectFrom: #superclass.
RSTreeLayout on: boxes.
canvas @ RSCanvasController.
canvas.
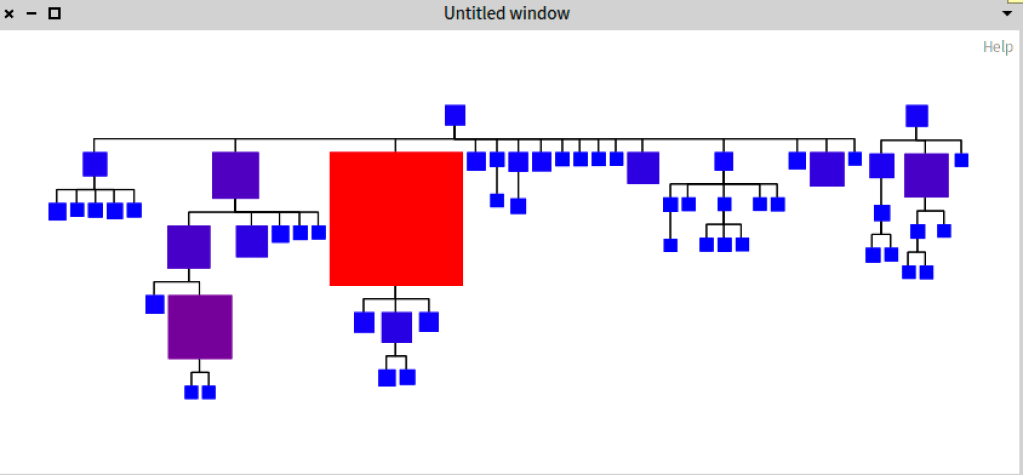
The execution of the previous script will produce the next image
This visualization shows a hierarchy of boxes, where each box is the graphical representation of a class. The width, height and color represent the size of the lines of code of the class. The lines show the connection or relationship between each class. In this case the connection is to the superclass of each class. The type of these lines is orthogonal vertical line. The position of each box shows a nice tree structure for the Collection with all subclasses.
Let’s analyse each part of the script:
Collecting data: getting a model for the visualization
data := Collection withAllSubclasses.
Usually when you are building a visualization, you use a group of objects, or collection of data. In this case our data is a collection of classes, but you can use CSV files, sql databases, or objects. In some cases you should preprocess your data before visualize it.
Generating shapes
Roassal uses several basic shapes to create the visualization, like RSBox, RSEllipse, RSLabel, RSLine, and RSComposite to combine them.
boxes := data collect: [ :class |
RSBox new
model: class;
popup;
draggable;
yourself ].
This script creates a drawable box shape for each class. This box has a model (the class it represents). In addition this code puts a popup and a drag and drop interactions.
Creating the canvas
In Roassal, an instance of RSCanvas is the default container of shapes to show your shapes. When you want to show a shape, create it and then add it into the canvas.
canvas := RSCanvas new.
canvas addAll: boxes.
Normalization
To understand the relation between our data or to stress an aspect, sometimes it is necessary to apply a normalization or transformation for some properties of the visual elements, like the width, height, color, etc.
RSNormalizer size
from: 10;
to: 100;
shapes: boxes;
normalize: #linesOfCode.
RSNormalizer color
from: Color blue;
to: Color red;
shapes: boxes;
normalize: #linesOfCode.
In this example we are using lines of code for each class to represent the color and the size of each box.
RSNormalizer size returns an instance of RSNormalizer, this object can modify the size(width and height) property for a group of shapes.
The methods from: and to: define the values from the minimum and the maximum values from the collection of shapes. That means that for the class that have the minimum number of lines of code the size of that box will be 10. And for the class with the maximum number of lines of code the size will be 100.
We use normalize: message to apply the transformation on each shape, using a block or method that takes as argument the model of each shape.
Lines
To show links between these boxes we can use lines.
A line builder has many parameters to create and add new lines to the canvas.
RSLineBuilder orthoVertical returns an instance of RSLineBuilder, orthoVertical, is the type of line that we want to use, we can use line, or bezier or etc.
withVerticalAttachPoint creates an attach point. This object knows the starting and ending point for the line.
This builder interacts with a group of shapes so we set it using the message shapes:.
connectFrom: is the method that will apply the builder and will generate new lines between the group of boxes, using #superclass for each box’s model.
If need it you can use directly the basic shapes RSLine or RSPolyline for some specific scenarios.
Layout
Finally a good visualization needs to put each element in the correct position by using a layout.
RSTreeLayout on: boxes.
canvas @ RSCanvasController.
canvas.
Roassal layout is an object that changes the position of shapes when the method on: is executed. You can use RSTreeLayout, RSVerticalLineLayout, RSHorizontalLineLayout, etc. There are many layouts in Roassal that you can use. You can also define your own layouts in case the default ones are not enough.
RSCanvasController puts basic interactions in the canvas, for zoom in or zoom out and navigate into the canvas. And the last line is the canvas itself to inspect it on the playground.
The next step: convert a script into a class
Using a script to prototype a visualization is handy and fast. However, it does not scale in terms of reusability and customization.
To reuse this code we need to create a class, there are many ways to do it. We suggest to create a subclass of RSAbstractContainerBuilder. Builders in Roassal, create a group of shapes set the interaction events and put each element in the correct position and they add the shapes into a canvas.
Create a Demo package in the system browser and then a new class TreeClassBuilder, this new class will create the same visualization as the script.
We should implement the method renderIn:. If we copy the previous script, but we omit the creation of the canvas, and then we declare the local variables and the we use the text code formatter, the method will be:
"hooks"
TreeClassBuilder >> renderIn: canvas
| data boxes |
data := Collection withAllSubclasses.
boxes := data collect: [ :class |
RSBox new
model: class;
popup;
draggable;
yourself ].
canvas addAll: boxes.
RSNormalizer size
from: 10;
to: 100;
shapes: boxes;
normalize: #linesOfCode.
RSNormalizer color
from: Color blue;
to: Color red;
shapes: boxes;
normalize: #linesOfCode.
RSLineBuilder orthoVertical
withVerticalAttachPoint;
color: Color black;
shapes: boxes;
connectFrom: #superclass.
RSTreeLayout on: boxes.
canvas @ RSCanvasController.
canvas
To test it in a playground execute this line: TreeClassBuilder new open. It will open a window with the same visualization as before. That means that open method calls renderIn: method.
Now we would like to customise each part of the script, for example different domain model(data), different shapes, different transformations. or lines, or event layout, using OOP.
Test driven development
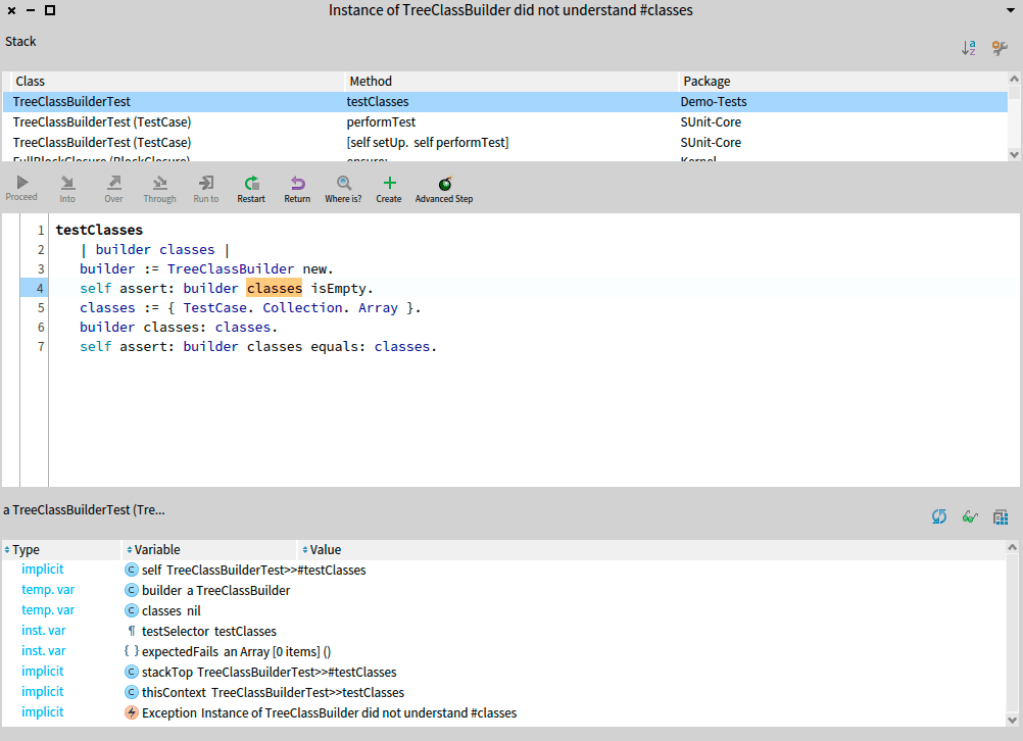
It is a good practice to use test cases, to create the test class, right-click over the class name and click over Jump to test class. Then we get the class TreeClassBuilderTest
We will need some tests, like the test that opens the window but this test needs to close/delete the opened window.
If we execute this test will fail. Because we do not have the accessor method for classes.
Using the debugger we can generate this this getter method, using the button Create, first we select the TreeClassBuilder, then we select/write the accessing protocol for the new method.
We return an instance variable classes,
"accessing"
TreeClassBuilder >> classes
^ classes
Then click on Proceed button on the debugger. We will have a new error: classes is nil. To solve it we can define a default value in the initialize method. Browse the class TreeClassBuilder and create initialize method as follow:
"initialization"
TreeClassBuilder >> initialize
super initialize.
classes := #().
The inspector is a central tool in Pharo as it allow one to (i) see the internal representation of an object, (ii) intimately interact with an object through an evaluation panel, and (iii) get specific visual representations of an object. These three properties and the fact that developers can define their own visualizations or representations of a given object makes the inspector a really powerful tool. In addition the inspector navigation will let the user smoothly walk through the objects each of them via specific or generic representations.
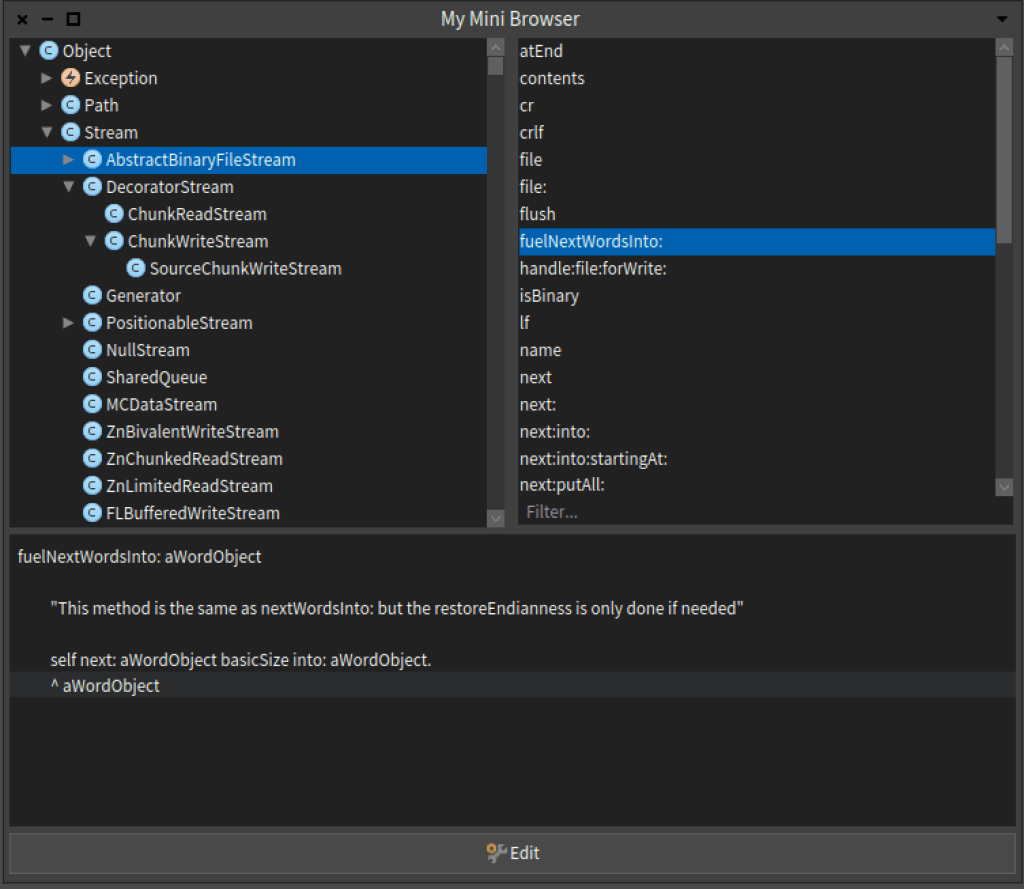
In this case our data domain are classes, we can define an inspector pane to show the hierarchy. Open the class Class in the system browser, then add the following method:
"*Demo"
Class >> inspectorTreeBuilder
<inspectorPresentationOrder: 1 title: 'Subclass Hierarchy'>
^ TreeClassBuilder new
classes: self withAllSubclasses;
asPresenter
The previous method is an extension method, for the package Demo, this means that the source code of this method will be save in the Demo package. By using the pragma <inspectorPresentationOrder:title:>, Pharo developers can define a new view pane for that object in the inspector.
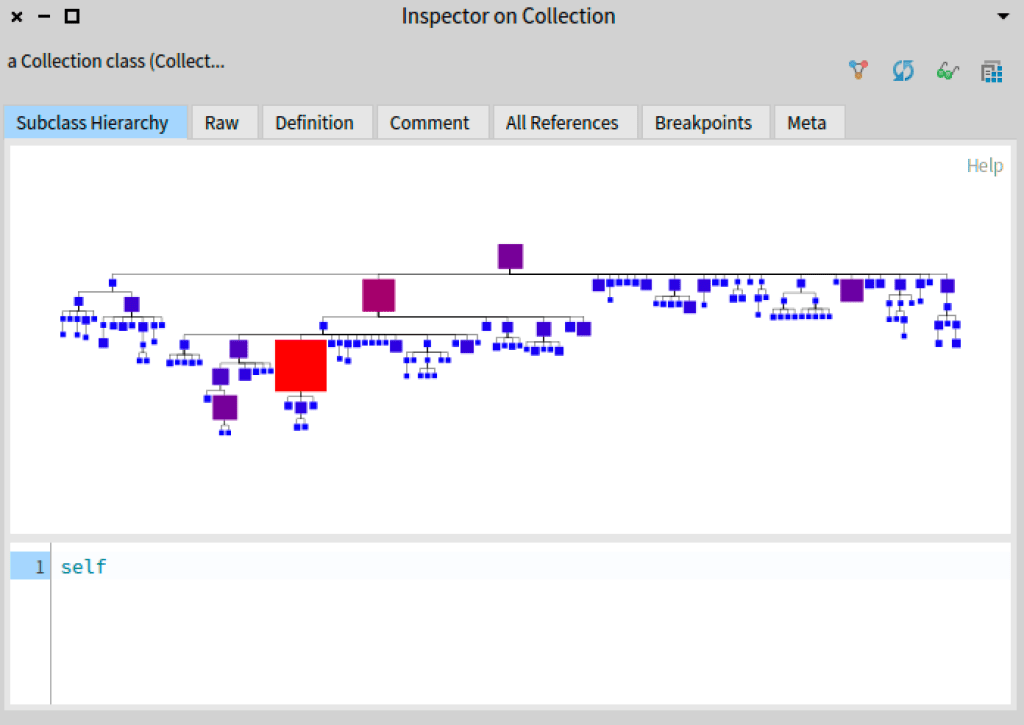
Also because our TreeClassBuilder is subclass of RSAbstractContainerBuilder, you can use the method asPresenter. Now execute: Collection inspect
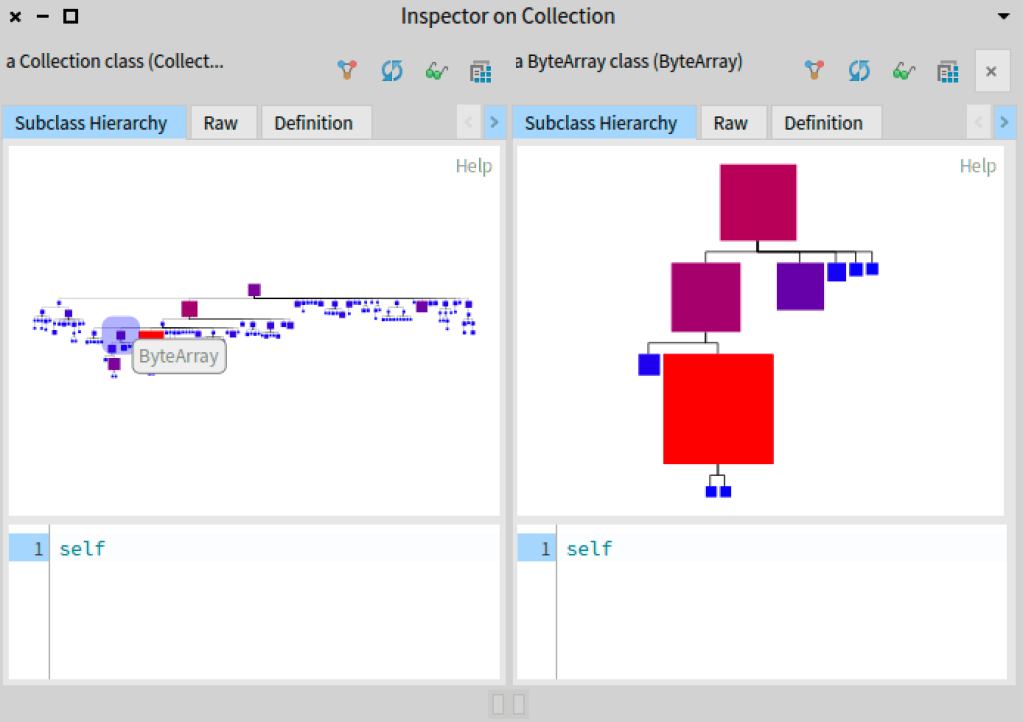
If you click over one box you will see the subclass hierarchy for the selected box in a new inspector pane.
With the approach presented in this article, you can extent any of your domain objects or event the ones offered by the system and have different views of the same object.
The inspector and its specific panes let the user navigation from one visualization to another. Such interaction and navigation constitute a context to ease the manipulation and understanding of domain or objects.
Export the visualization to other formats
To export in other image formats like PNG, PDF, SVG, we need the project Roassal3Exporters, use the next incantation in a playground:
Metacello new
baseline: 'Roassal3Exporters';
repository: 'github://ObjectProfile/Roassal3Exporters';
load.
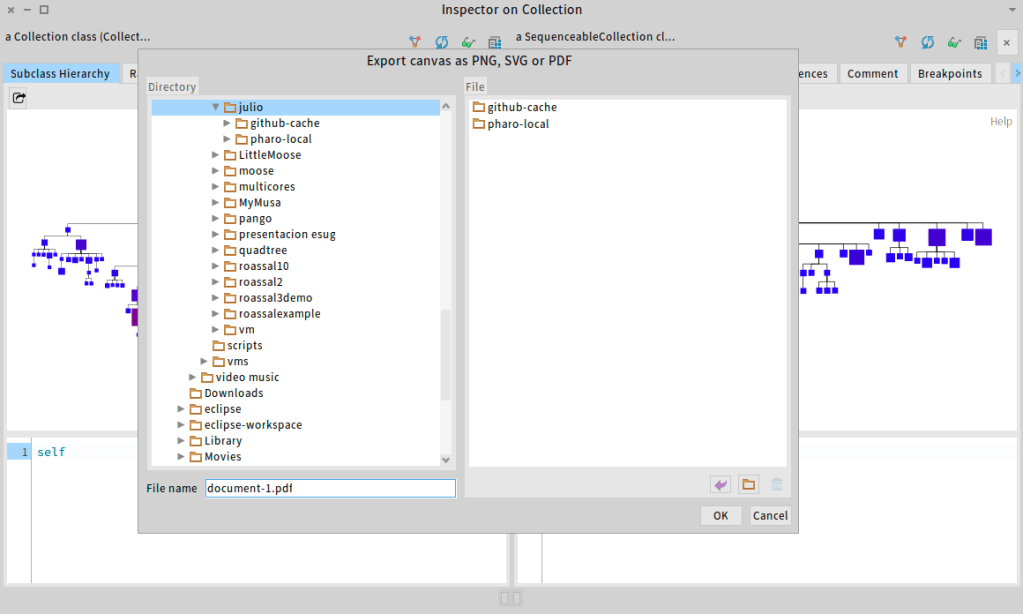
After that we need to reopen the inspector. And we will find a new toolbar button
The button will open a file chooser window where we can use SVG, PNG or PDF file formats
You can use more file formats with different constraints. like html using https://aframe.io/ or mp4 files o video files with transparency using https://ffmpeg.org/.
Share the code in Github
Finally, to share our cool project with the people we will need to create a repository in a git server like Github.
We saw how to create a new visualization from scratch and how it can be scaled into a class. In addition, Pharo provides many tools in the development of basic and complex applications such as: the Inspector, the Debugger, Spec, Roassal, Iceberg, etc.
We show how we can extend the environment to be able to use our new visualization.
We saw that use can use Roassal visualizations to get a different perspective on domain objects. We show that a new visualization can be tested, shared and used by other developers. You also can use projects like: Athens-Cairo, Morphic or other backends such as GTK. But Roassal offers many tools to interact manipulate and talk with your object data.
In this post, I will explain what is a transmission, a transformation and how to have custom transmissions in the Pharo Inspector. We will show how transmissions are used in the inspector with a soccer database analysis tool that you can find at https://github.com/akevalion/Futbol/. We used this application because we needed a real domain to navigate within the inspector and to show some non-trivial situations where you want to abstract over the domain to get a smooth navigation flow.
In particular, the inspector is a special object presenter that control the navigation between spec presenters. And we will explain such a specific case.
So let us start by explaining transmissions.
What is a transmission?
Transmissions are a generic way to propagate information between Spec components. They are a way to connect presenters, thinking on the “flow” of information more than the way it is displayed.
For example, let us say that we want to have a presenter with a list and with a text inside. When one clicks on the list, the text inside the text presenter will update.
But this does not say how list and detail are linked. We could do it by describing action to be raised on specific list events or via transmissions.
The transmission sub-framework solves this in an elegant way: Each presenter defines ”output ports” (ports to send information) and ”input ports” (ports to receive information). Each presenter defines also default input and output ports.
Transmitting
A transmission connects a presenter’s output port with a presenter’s input port using the message transmitTo: as follows:
list transmitTo: detail.
This will connect the list presenter default output port with the detail presenter default input port. This line is equivalent (but a lot simpler) to this one:
list defaultOutputPort transmitTo: detail defaultInputPort.
It is important to remark that a transmission does not connect two components, it connects two component ports. The distinction is important because there can be many ports! Take for example the class SpListPresenter, it defines two output ports (selection and activation), this means it is possible to define also this transmission (note that we do not use the defaultInputPort but outputActivationPort instead):
list outputActivationPort transmitTo: detail defaultInputPort
Note that some presenters such as SpListPresenter offer selection and activation events (and ports). An activation event is a kind of more generic event. Now the selection event can be mapped to an activation event to provide a more generic layer.
Transforming values during a transmission
The object transmitted from a presenter output port can be inadequate for the input port of the target component. To solve this problem a transmission offers transformations. This is as simple as using the transform: message as follows:
list
transmitTo: detail
transform: [ :aValue | aValue asString ]
We can also transmit from an output port to an arbitrary input receiver using the message transmitDo: and transmitDo:transform:. It is possible that the user requires to listen an output port, but instead transmitting the value to another presenter, another operation is needed. The message transmitDo: message handles this situation:
list transmitDo: [ :aValue | aValue crTrace ]
Acting after a transmission
Sometimes after a transmission happens, the user needs to react to modify something given the new status achieved by the presenter such as pre-selecting an item, shading it… The postTransmission: message handles that situation.
list
transmitTo: detail
postTransmission: [ :fromPresenter :toPresenter :value |
"something to do here" ]
Transforming transmissions inside the Inspector
We will use as an example for this blogpost a football project. You can download it from herehttps://github.com/akevalion/Futbol/. There are instructions in the README of how to install it. The project allows one to visualise a european football database. Note that installing the project may take some minutes because it needs to install the database.
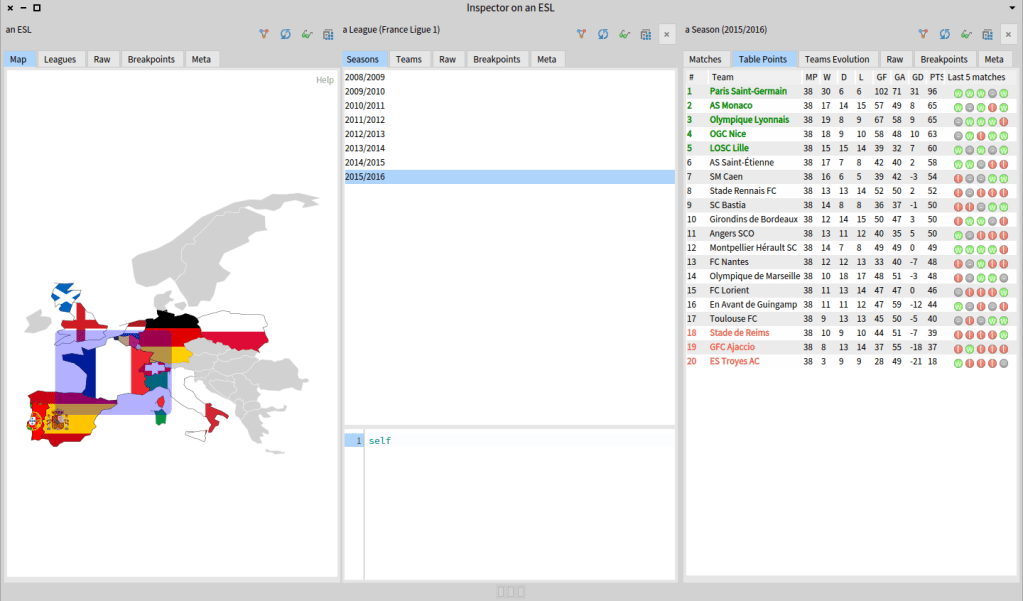
Teaser of the project
First, we can select the country league that we would like to see. In this case we choose France. Then we see a list with the seasons available. We select a season and we can see a table of points of that season of the French league.
The problem
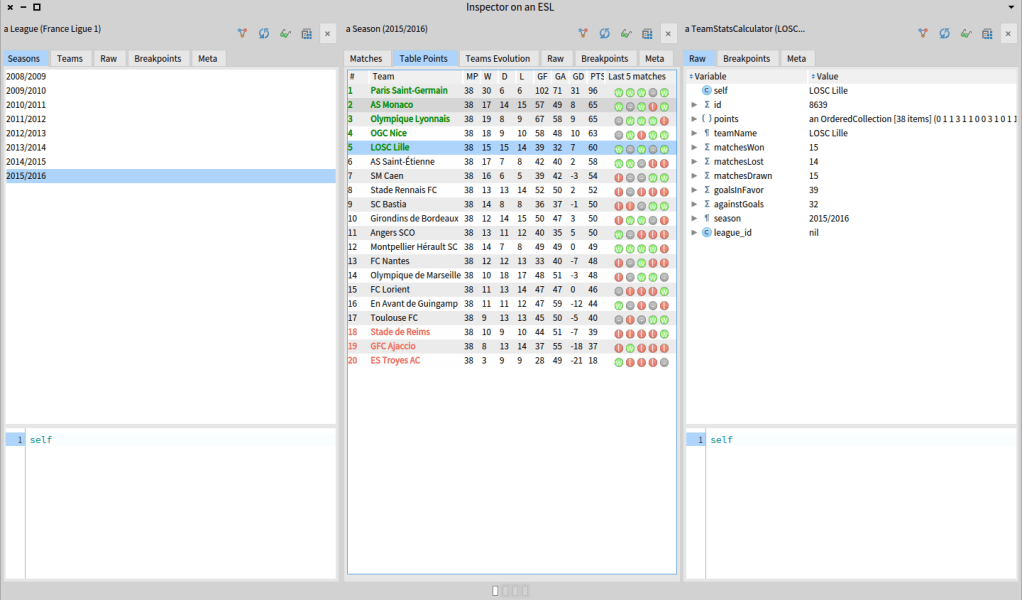
For calculating the statistics of a team, we use a calculator class (TeamStatsCalculator) and not the real model. This is a common situation in which one needs to use a helper class not to pollute the model. So, if we click on a team of the table, instead of seing a soccer team object, which is what we would expect, we see a TeamStatsCalculator instance. In this example, we clicked on the team LOSC of Lille but we get a TemStatsCalculator instead of the LOSC team (yes our team is located at Lille so we took a local team).
What we would like to have is to transform the transmission. The class TeamStatsCalculator knows its real Team and it knows how to convert itself into an instance of Team with the message TeamStatsCalculator >> asTeam. So, we want to transform the object into an instance of Team and then transmit it.
Now there is a catch, as we are inside the inspector, doing the transformation is not the same as before because the inspector takes control of the presenter.
Using SpTActivable trait
SpTActivable is a trait that helps us to use transmission in the Inspector.
We need to use that trait in the class of our presenter. For this example we will use the trait in the class TablePointsPresenter, that is our presenter class that is used inside the inspector.
Once we user that trait, we need to define the method: outputActivationPort on our TablePointsPresenter class.
The method will say how we are going to transform the element. As we said previously, in this case, we only need to send the message asTeam to the object and it will return an instance of its real team when we click on an item of the table. To define the outputActivationPort method, we need to return an instance of SpActivationPort and specify the transform action.
For this example, we will return the output activation port of the table and to specify the transformation.
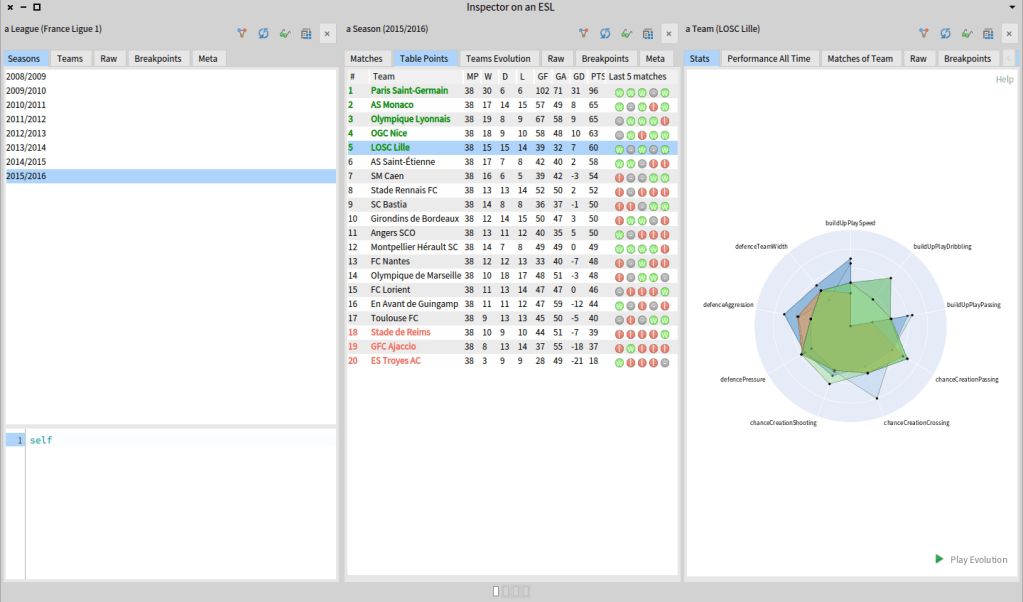
Now, we refresh the inspector, and when we click on a row and we see that now we have the real team object for the LOSC of Lille!
Conclusion
We saw that to transform value during a transmission in the Pharo Inspector, we only need to use the trait SpTActivable and to define the method outputActivationPort. Also, we saw how thanks to the transmissions sub-framework this work is easy to do as Spec takes care of it for us.
To work on Pharo’s virtual machine, you’ll need to set up both the virtual machine you’ll be modifying, as well as a Pharo image. Below are the instructions required to set up the environment. You will need both the VM and the image containing the VM compilation chain (VMMaker package).
Imagine that you want to find a specific expression and that you want to find it in the complete system. How many classes would you have to look for? How can you be sure that you did not miss any class and being sure that you won’t be frustrated because of the number of issues thrown on compilation or execution? In addition imagine other scenario where you want to transform that expression into another one.
Changing code, removing, or replacing deprecated methods is costly for a developer by doing it manually instead of using an automated feature.
This blog post will explain how to find a specific piece of code we may look for inside a Pharo program, and make it easy for the developers to deal with pattern matching and RBParseTreeSearcher class.
Following work will be about how to replace code using RBParseTreeRewriter and doing the exact same thing automatically using the Rewrite tool (a tool built on top the RBParseTreeRewriter).
For the moment, we will explain some fundamental definitions and for that the post is structured following below sections:
Pattern code description
RBParseTreeSearcher description
RBParseTreeSearcher examples with pattern code
1. Pattern code description
A pattern expression is very similar to an ordinary Smalltalk expression, but allows one to specify some “wildcards”. The purpose is simple. Imagine that you have a piece of code:
car isNil ifTrue: [ ^ self ].
You can of course compare it with the same piece of code for equality, but wouldn’t it be cool if you could compare something similar, but ignore the fact that the receiver is named car? With pattern rules you can do exactly that. Consider the following code and notice the back-tick before car:
`car isNil ifTrue: [ ^ self ].
Now this expression can match any other expression where isNil ifTrue: [^self]is sent to any variable (or literal). With such a power you can find all the usages of isNil ifTrue: and replace them withifNil. So what are the “wildcards” that we are using?
(`)Basic pattern nodes
Code prefixed with a back-tick character (`) defines a pattern node. The table below is listing three simple patterns that can be declared with the back-tick:
Pattern type
Example
Description
Variable
`someName asString
This pattern will match message asString sent to any receiver, disregarding the name of it
Message
Pharo globals `someMessage
This pattern will match any unary message sent to Pharo globals.
Method
`someMethod ^ nil
This pattern will match any method which returns nil
Selector
`sel: aVal
This pattern will match any selector followed by aVal.
Example with matches:
`receiver foo
matches:
self foo
x foo
OrderedCollection foo
(`#) Literal pattern nodes
A back-tick can be followed by the hash sign to ensure that matched receiver will be a literal:
Pattern type
Pattern node
Description
Literal
`#literal asArray
This pattern will match any literal (Number, String, Array of literal ) followed by asArray message
Example:
`#lit size
matches:
3 size
'foo' size
#(a b c) size
(`@) List pattern nodes
To have complete flexibility, there is the possibility to use an at sign @ before the name of a pattern node which turns the node into a list pattern node, which can be empty, returns one or multiple values.
Pattern type
Pattern node
Description
Entity
`@expr isPatternVariable
This pattern will match a single or multiple entities followed by isPatternVariable
Message
myVar `@message
This pattern will match any message (including unary) sent to myVar
Temporary variable
|`temp `@temps|
This pattern will match at least one temporary variable which is defined as `temp; For`@temps, the matching can find nil, one or many temporary variables defined.
Argument
myDict at: 1 put:`@args
This pattern will match myDict at: 1 put: followed by a list of arguments `@args that can be nil, one or many args.
List of statements
[ `.@statements. `var := `myAttribute. ]
We will explain statements later on, but this is to mention that @ can be used also to define a list of statements which can be empty, contain one or many elements.
This expression will match a block which has at first a list of statements, that must be followed by 1 last assignment statement `var := `myAttribute.
Disclaimer:
You may write an expression with just args instead of `@args.
The list patterns does not make any sense for literal nodes i.e. `#@literal.
Example 1:
`x := `@value
matches:
myVar := OrderedCollection new
Example 2:
`sel1 at: `@args1 `sel2: `@args2
matches:
self at: index putLink: (self linkOf: anObject ifAbsent: [anObject asLink])
P.S. In the end it does not matter whether you will write `.@Statement or `@.Statement.
(`{ }) Block Pattern Nodes
These are the most exotic of all the nodes. They match any AST nodes like a list pattern and test it with a block. The syntax is similar to the Pharo block, but curly braces are used instead of square brackets and as always the whole expression begins with a back-tick.
this pattern will match a message #become: with an attribute nil, where the receiver is a variable and it is a global variable.
There is also a special case called wrapped block pattern node which has the same syntax and follows a normal pattern node. In this case first the node will be matched based on its pattern, and then passed to the block. For example:
`#arr `{ :node | node isLiteralArray } asArray
is a simple way to detect expression like#(1 2 3) asArray. In this case first #(1 2 3) will be matched by the node and then tested by the block.
Naming is Important
The pattern nodes are so that you can match anything in their place. But their naming is also important as the code gets mapped to them by name. For example:
`block value: `@expression value: `@expression
will match only those #value:value: messages that have exactly the same expressions as both arguments. It is like that because we used the same pattern variable name.
2. RBParseTreeSearcher description
So, after figuring out what are the patterns that can be used and what kind of matches they can perform, now we can move forward to discover how RBParseTreeSearcher class works in Pharo , in order to be able to understand in the last section how RBParseTreeSearcher and defined patterns work together to find the matches we are looking for.
RBParseTreeSearcher is supposed to look for a defined pattern using the ‘wildcards’ of a matcher defined as a Tree, and on success (when match is found) a block can be executed.
Basically, when a developper uses this class, the most used instance variables are:
#matches:do: which a message that looks for patterns defined in matches: block using the wildcards, and if a match is found the do: block is executed. The do block takes two parameters: :aNode and :answer. The aNode refers to each node of the pattern defined, and the answer can be used for example to increment value on each node match. The blocks defined in #matches:do: are called rules, and they are stored only in success in instance searches of RBParseTreeSearcher defined below.
searches which type is Ordered collection, contains all the successful rules applied whenever using: #matches:do:,#matchesMethod:do … to store rules of type Rule, MethodRule,ArgumentRule, TreeRule …
context which type is dictionary: contains all the successfully matched patterns.
executeTree:this method takes aParseTree as input parameter, which is the possible matching code that we are looking for, and starts the matching process using the defined pattern.
messages of type OrderedCollection, and returns the list of messages found in a match.
hasRules returns searches list
Consider the following example which is using the instance sides defined above:
The method #matches:do: is used to define the pattern that we are looking for, using the ‘wildcards’ defined in first section; In addition of that, the do is running only on match, and in our case it will fill the dictionary dict with the searcher context(which is the pattern defined in matches block). This execution is fired on executeTree:which defines the matcher that is a String parsed as a Tree using parseExpression, then starts matching it with the pattern.
3. RBParseTreeSearcher examples with pattern code
Finally, in this section we use patterns with the RBParseTreeSearcher class and do some magic by finding some matches in Pharo code !
The example is matching successfully and the dictionary dict will return different values during the iteration:
Match 1: (key) `@receiver is matching with (value) self Match 2: (key) `@arg is matching with (value) reader storedSettings first realValue
If we want to check all the messages in the matcher, we can use searcher messages which will return an array of one item containing message #assert:equals: as it is the only message available in the matched expression.
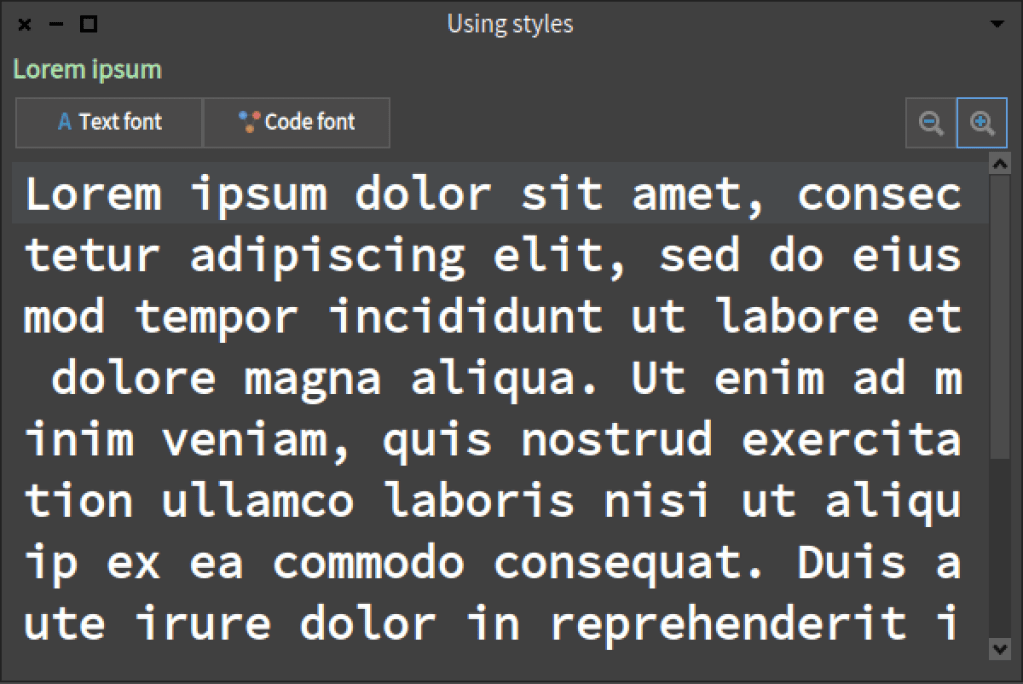
In this post we will see how to use custom styles in Spec applications. We will start to present styles and then build a little editor as the one displayed hereafter.
We will show that an application in Spec manages styles and let you adapt the look of a presenter.
How do styles work?
Styles in Spec work like CSS. They are style sheets in which the properties for presenting a presenter are defined. Properties such as colors, width, height, font, and others. As a general principle it is better to use styles instead of fixed constraints, because your application will be more responsive.
For example, you want a button to have a specific width and height. You can do it using constraints with the method add:withConstraints: or using styles. In both cases the result will be this:
But, if you change the size of the fonts of the Pharo image using Settings/Appearance/Standard Fonts/Huge, using fixed constraints, you will obtain the following result. You will for example do not be able to see the icons because the size is not recomputed correctly.
If you use styles, the size of the button will also scale as shown below.
Style format
The styles in Spec format are similar to CSS. Style style sheets are written using STON as format. We need to write the styles as a string and then parse it as a STON file.
Here is an example that we will explain steps by steps below.
SpPropertyStyle has 5 subclasses: SpContainerStyle, SpDrawStyle, SpFontStyle, SpTextStyle, and SpGeometryStyle. These subclasses define the 5 types of properties that exist. On the class side, the method stonName that indicates the name that we must put in the STON file.
SpDrawStyle modifies the properties related to the drawing of the presenter, such as the color and the background color.
SpFontStyle manipulates all related to fonts.
SpGeometryStyle is for sizes, like width, height, minimum height, etc.
SpContainerStyle is for the alignment of the presenters, usually with property is changed on the main presenter, which is the one that contains and arranges the other ones.
SpTextStyle controls the properties of the SpTextInputFieldPresenter.
If we want to change the color of a presenter, we need to create a string and use the SpDrawStyle property, which STON name is Draw as shown below. For setting the color, we can use either the hexadecimal code of the color or the sender of Color class.
Now we have two styles: lightGreen and lightBlue that can be applied to any presenter.
We can also use environmental variables to get the values of the predefined colors of the current theme, or the fonts. For example, we can create two styles for changing the fonts of the letters of a presenter:
'.application [
.codeFont [ Font { #name: EnvironmentFont(#code) } ],
.textFont [ Font { #name: EnvironmentFont(#default) } ]
]'
Also we can change the styles for all the presenters by default. We can put by default all the letters in bold.
'.application [
Font { #bold: true }
]'
Defining an Application
To use styles we need to associate the main presenter with an application. The class SpApplication already has default styles. To not redefine all the properties for all the presenters, we can concatenate the default styles (SpStyle defaultStyleSheet) with our own. As said above, the styles are actually STON files that need to be parsed. To parse the string into a STON we can use the class SpStyleVariableSTONReader.
We can use different properties in the same style. For example, in labelStyle we are setting the height of the presenter to 25 scaled pixels and the font size to 12 scaled pixels. Also, we are using EnvironmentColor(#base)for obtaining the default background colour according to the current theme. Because the colour will change according to the theme that used in the image.
For the main presenter, we will build a mini-text-viewer in which we will be able to change the size and the font of the text that we are viewing.
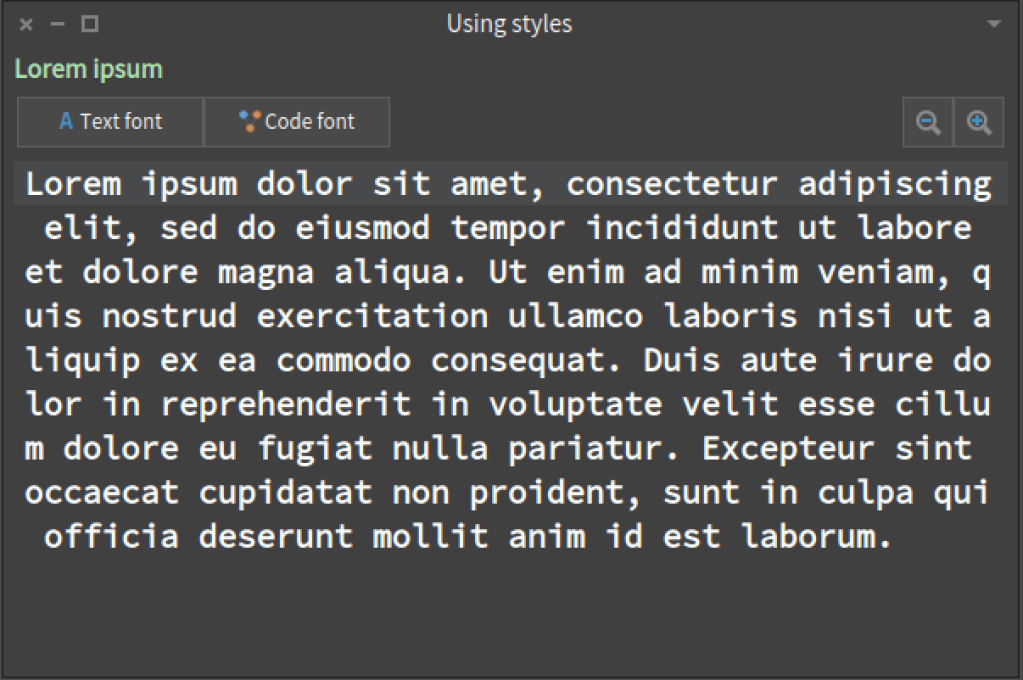
Without setting the custom styles nor using our custom application in the presenter, we have:
We do not want the black background color for the text presenter. We will like to have a sort of muti-line label. We want the zoom buton to be smaller as they only have icons. We want to have the option to change the size and font of the text inside the text presenter. Finally, why not, we want to change the color of the label, change the height and make it a little more bigger.
CustomStylesPresenter >> initializeStyles
"Change the height and size of the label."
label addStyle: 'labelStyle'.
"But the color as light green"
label addStyle: 'lightGreen'.
"The default font of the text will be the code font and the size size will be the small one."
text addStyle: 'codeFont'.
text addStyle: 'smallFontSize'.
"Change the background color."
text addStyle: 'bgOpaque'.
"But a smaller width for the zoom buttons"
zoomInButton addStyle: 'icon'.
zoomOutButton addStyle: 'icon'.
codeFontButton addStyle: 'buttonStyle'.
textFontButton addStyle: 'buttonStyle'.
"As this presenter is the container, set to self the container
style to add a padding and border width."
self addStyle: 'container'
Finally, we have to override the start method in the application. With this, we are going to set the application of the presenter and run the presenter from the application.
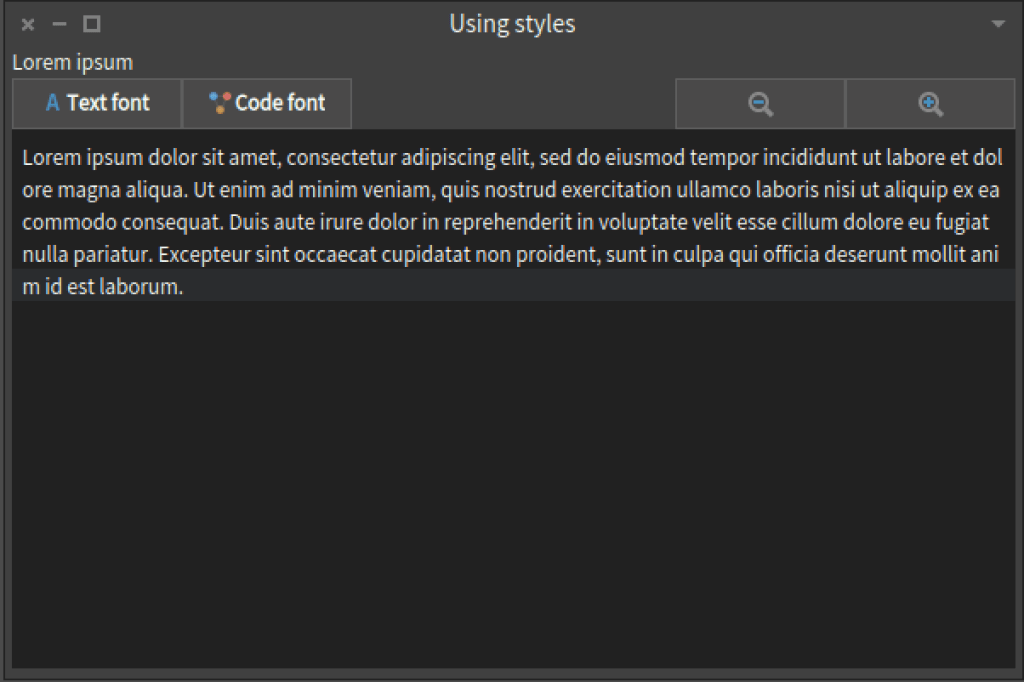
Now, if we run CustomStylesApplication new start we will have:
The only thing missing is to add the behaviour when pressing the buttons.
For example, if we click on the zoom in button we want to remove the smallFontStyle and add the bigFontSize. Or, if we click on the text font button, we want to remove the style codeFont and add the textFont style. So, in the connectPresenters method we have:
CustomStylesPresenter >> connectPresenters
zoomInButton action: [
text removeStyle: 'smallFontSize'.
text addStyle: 'bigFontSize' ].
zoomOutButton action: [
text removeStyle: 'bigFontSize'.
text addStyle: 'smallFontSize'].
codeFontButton action: [
text removeStyle: 'textFont'.
text addStyle: 'codeFont' ].
textFontButton action: [
text removeStyle: 'codeFont'.
text addStyle: 'textFont']
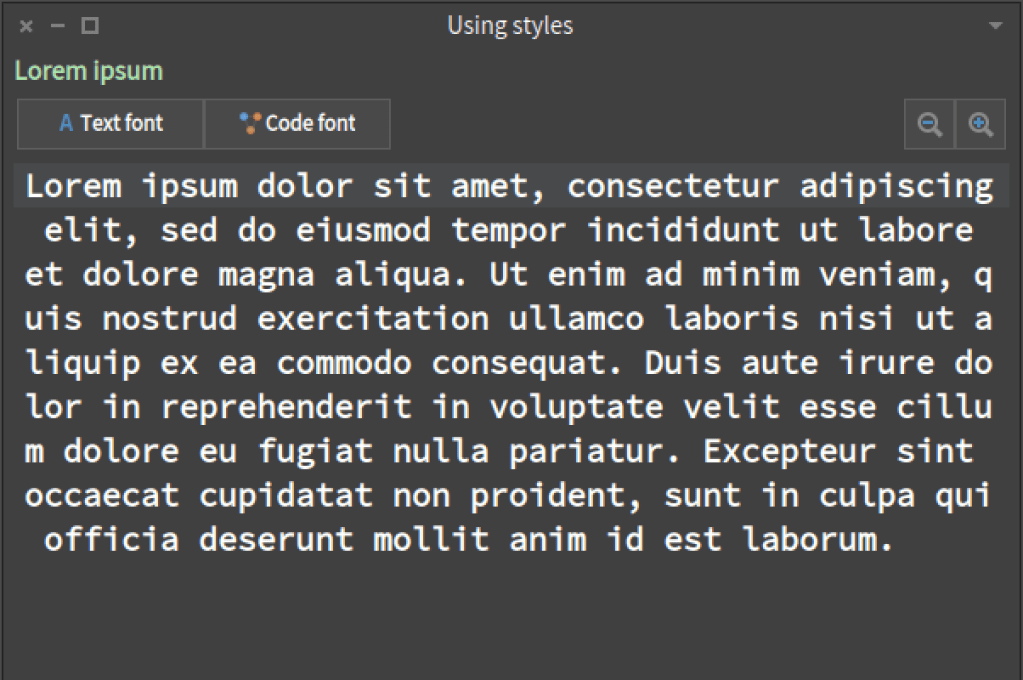
Now, if we click on zoom in we will have:
And if we click on text font:
Conclusion
Using styles in Spec is great. It make easier to have a consistent design as we can add the same style to several presenters. If we want to change some style, we only edit the styles sheet. Also, the styles automatically scale if we change the font size of all the image. They are one of the main reason why in Spec we have the notion of an application. We can dynamically change how a presenter looks.
In this post I am going to show you how to call external functions from a Pharo image. Here, we are going to use the LAPACK (Linear Algebra Package) library that is written in Fortran.
Why do we need this library?
In the Pharo AI project (https://github.com/pharo-ai), we are working on an implementation of linear regression. Currently, we are writing the logic completely in Pharo. But, linear regression can be formulated in terms of least squares and Lapack implements efficiently the minimum-norm solution to a linear least squares problem.
So we want to get the best of the two worlds: nice objects in Pharo and call some fast and low-level libraries for crunching numbers. We want to bind the routine dgelsd() that does exactly what we want.
Implementing the binding
We need to have the library already installed in our machines. As a first step, we create a subclass of FFILibrary called LapackLibrary and we need to override the methods: macLibraryName, win32LibraryName and unixLibraryName. In those methods we should return the path in which the library is installed. For MacOS, we override the macLibraryName method as follows:
For using this binding on Linux is only needed to override the remaining method. One can use the class FFIUnix32LibraryFinder or FFIUnix64LibraryFinder.
Now, we are going to create the class LapackDgelsd. We override the method ffiLibrary to return just the class LapackLibrary.
LapackDgelsd >> ffiLibrary
^ LapackLibrary
Now we can implement the method which will eventually make the FFI call. We saw in the documentation that dgelsd receives 14 parameters, all pointers, that have different types. To make the FFI call we have to use self ffiCall: and inside put the signature of the foreign function.
The variables that are passed must be either local or instance variables. We can specify the type of each of the variables, or we can say that the type is void*. That means that the FFI library is not going to do the mapping to the correct type, but is a responsiblity of the programmer to instantiate the variables with the correct type. So, we get:
LapackDgelsd >> ffiDgelsdM: m n: n nrhs: nrhs a: a lda: lda b: b ldb: ldb s: s rcond: rcond rank: aRank work: work lwork: lwork iwork: iwork info: anInfo
^ self ffiCall: #( void dgelsd_(
void* m,
void* n,
void* nrhs,
void* a,
void* lda,
void* b,
void* ldb,
void* s,
void* rcond,
void* aRank,
void* work,
void* lwork,
void* iwork,
void* anInfo ) )
In the documentation of the routine , we see that we need integer pointers, double pointers, integer arrays, and double arrays. To use pointers in Pharo, we need to use the class FFIExternalValueHolder. It actually will create an anonymous class of the type that we need. To ease the work, we will create a helper class that will create the pointer for us.
We can name the class LapackPointerCreator and that class has to have two class variables: DoublePointerClass and IntegerPointerClass. In the initialize method of the class, we instantiate the value of the class variables to be:
LapackPointerCreator class >> initialize
DoublePointerClass := FFIExternalValueHolder ofType: 'double'.
IntegerPointerClass := FFIExternalValueHolder ofType: 'int'
And then we create the two helper methods:
LapackPointerCreator class >> doublePointer: aNumber
^ DoublePointerClass new value: aNumber
LapackPointerCreator class >> integerPointer: aNumber
^ IntegerPointerClass new value: aNumber
And we will also create an extension method of Collection to convert a collection into n FFI external array.
Now we are ready to make the call to the Lapack dgelsd() routine. We are going to follow this example of how to use dgelsd() with the same values. First, we need to create all the variables that we are going to pass as arguments.
The WORK array is a workspace that is used internally by the dgelsd() routine. We must allocate the memory for this array before passing it to the routine. To calculate the optimal size of the WORK array, we run the dgelsd() routine with LWORK value -1 and WORK as any pointer. After this first execution, the optimal workspace size will be written into the WORK pointer. Therefore, we will be making two FFI calls to the routine: first to calculate the optimal workspace and then to find the solution to the least squares problem.
Now, the variable workPointer contains the value of the optimal workspace. With that information, we run the dgelsd() routine again to solve the problem for matrices A and B.
The result of the computation is stored in several variables. For example, the values of matrixB have been replaced with the minimum norm solution. The effective rank is contained in the rankPointer and the S array contains the singular values of matrix A in decreasing order. The INFO variable contains an integer value that informs us whether the routine succeded or failed (0 = successful exit).
To see the value of a pointer, we can use the value message, for example, rankPointer value.
Improving the API
Make the call to the Fortran routine was a little tricky. We don’t want to give the user the responsibility of creating all of those pointers for using the not-so-nice method signature. So we will use Pharo in our favour.
Actually, we only need to set 5 values of the method, the rest can be calculated internally. What we will do is to have all the needed variables as instance variables of the class LapackDgelsd. Like:'matrixA matrixB numberOfRows numberOfColumns numberOfRightHandSides leadingDimensionA leadingDimensionB singularValues rank info reciprocalConditionNumber workArraySize minimumNormSolution iworkArray'.
Then, we will create the setters for the 5 values that we need the user to insert. Note that the user does not need to create any pointer. They pass only a Pharo Array.
Now, as we do not want to give the responsiblity to the user to call the method twice, one for obtaining the optimal workspace and then for solving the actual equation. We will create a solving method that does all the work. We have:
This is definitively better, since it hides the implementation details of the underlying implementation. And for getting the solution, we only need to call these accessors:
"Info represents if the process completed with success"
algorithm info.
"The array with the solutions"
algorithm minimumNormSolution.
"The effective rank"
algorithm rank.
"And the singular values of matrix A"
algorithm singularValues.
Conclusion
As we saw, doing the binding for the first method was the hardest part. But all the next methods will be easier to implement because we can use the same infrastructure.
Here we showed a binding for a widely used linear algebra library. That will help us to speed up the mathematical computations of libraries such as PolyMath (https://github.com/PolyMathOrg/PolyMath/) and Pharo-AI (https://github.com/pharo-ai). Lapack is a huge library so we don’t want to bind all the methods, but only the ones that we need. If people from the community would like us to migrate other methods of the library, we will be happy to do it. We will work on demand. The code and instructions are available here.
Our next step is to use dgelsd() in our linear regression implementation in Pharo for benchmarking against Python and R. Because those languages use also Lapack fortran library and they are considered as industry standards.
As you may already know, Spec2 is the new version of the UI framework: Spec. Spec2 is not just a new version but a complete rewrite and redesign of Spec1. Contrary to Spec1, in Spec2 all the layouts are dynamic. It means that you can change on the fly the elements displayed. It is a radical improvement from Spec1 where most of the layout were static and building dynamic widgets was cumbersome.
In this post we will show that presenters can be dynamically composed using layouts. We will show a little interactive section. Then we will build a little code editor with dynamic aspects. Note that In this post, we are going to use simply Spec, to refer to Spec2 when we do not need to stress a difference.
Layouts as simple as objects
Building dynamic applications using Spec is simple. In fact, any layout in Spec is dynamic and composable. For example, let me show you the following code snippet:
"Instantiate a new presenter"
presenter := SpPresenter new.
"Optionally, define an application for the presenter"
presenter application: SpApplication new.
There are three principal layouts in Spec: SpPanedLayout, SpBoxLayout and SpGridLayout. For this presenter we will use the SpPanedLayout, which can receive two presenters (or layouts) and places them in one half of the window.
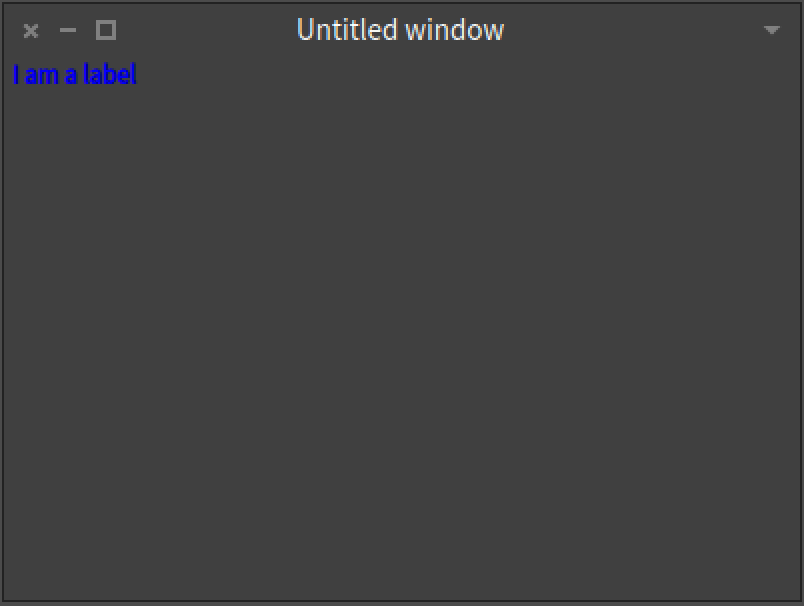
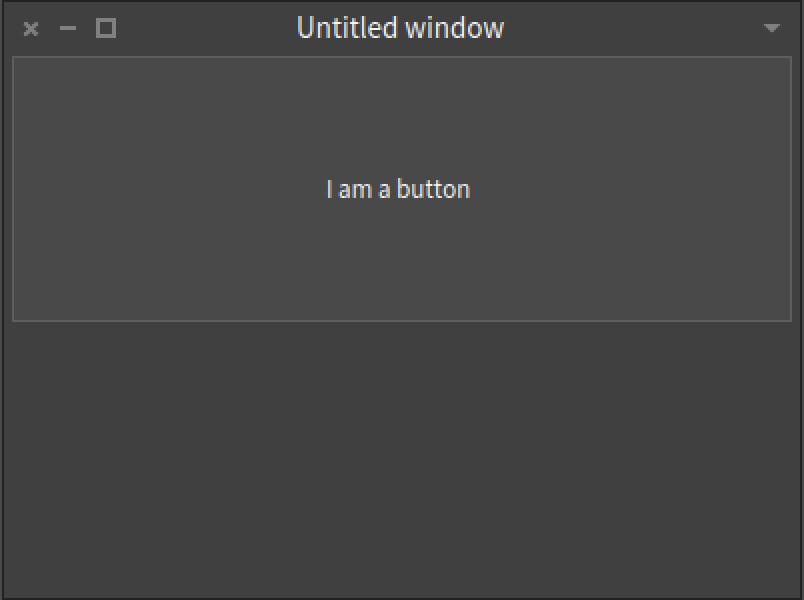
Of course, we are going to see an empty window because we did not put anything in the layout.
Empty layout
Now, without closing the window, we can dynamically edit the layout of the main presenter. We will add a button presenter executing the following lines:
presenter layout add: (button1 := presenter newButton).
button1 label: 'I am a button'.
Paned layout with one button
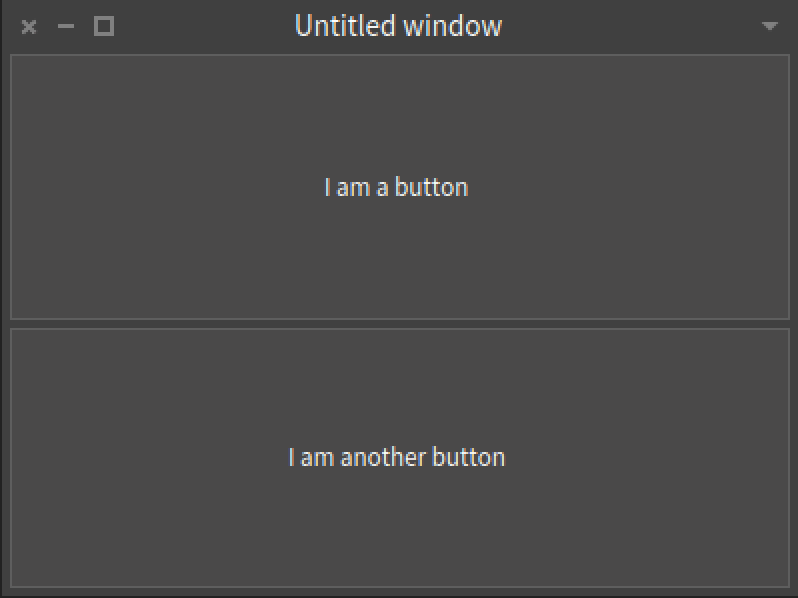
Now, we can add another button. There is no need to close and reopen the window, everything updates dynamically and without the need of rebuilding the window. As we instantiate the layout with newTopToBottom, the presenters will align vertically.
presenter layout add: (button2 := presenter newButton).
button2 label: 'I am another button'.
Paned layout with two buttons
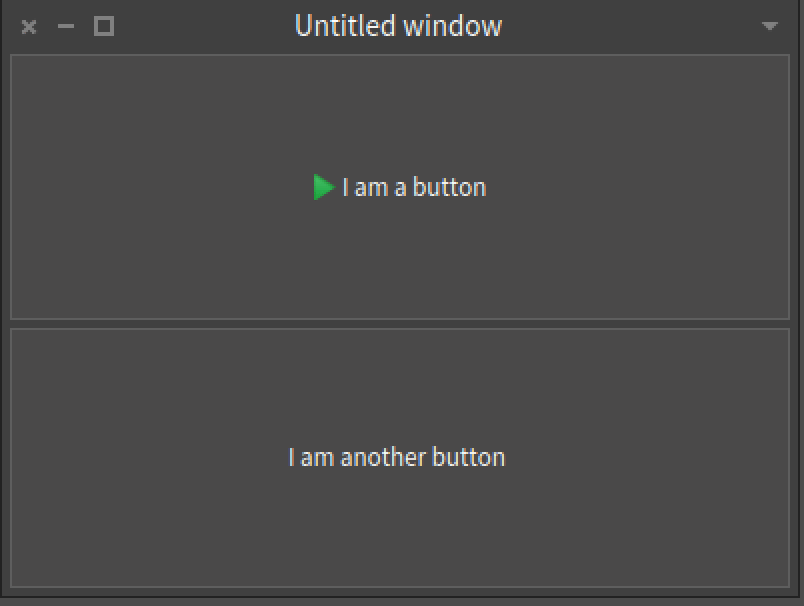
Now, we can put an icon for the first button:
button1 icon: (button1 iconNamed: #smallDoIt).
Paned layout
Or we can delete one of the buttons from the layout:
presenter layout remove: button2.
What we should see here is that all the changes happens simply by creating a new instance of a given layout and sending messages to it. It means that programs can create simply complex logic of the dynamic behavior of a widget.
Building a little dynamic browser
Now, with all of this knowledge, we are going to build a new mini version of the System Browser. We want to have
A tree that shows all the system classes.
A list that shows all methods in the selected class.
A text presenter that show the code of a selected method and a button.
Initially the code of the method will be in “Read-Only” mode. When we press the button, we are going to pass to “Edit” mode.
Let us get started. So, first, we need to create a subclass of SpPresenter, called MyMiniBrowserPresenter.
Now, we need to override the initializePresenters method in which we are going to initialize the presenters and the layout of our mini browser.
First we are going to instantiate the tree presenter. We want the tree presenter to show all the classes that are presented in the Pharo image. We know that all subclasses (almost) inherit from Object. So, that is going to be the only root of the tree. To get the subclasses of a class we can send the message subclasses, that is what we need to get the children of a node. We want to each of the nodes (clases) have a nice icon, we can get the icon of a class with the message systemIcon. Finally, we want to “activate” the presenter with only one click instead of two. The code will be:
For the methods, we want to have a filtering list. That means, a list in which we can search of elements. Also, we want that to display only the selector of the method to the user and sort them in an ascending way.
We said that, initially, the code is going to be in “Read-Only” mode. So, the label of the button is going to be “Edit” so say that is we click on the button we will change to edition mode. Also we want to have a nice icon.
We want in the upper part of the layout to have the classes and the methods shown in a horizontal way, like in the System Browser (a.k.a. Calypso). So, what we will do is to create another left to right layout, with an spacing of 10 pixels, the classes and the methods.
Then, we will add that layout to our main layout. the main layout is going to be a top to bottom layout. After, we want the code shower and then the button. We do not want the code to expand and also we want a separarion of 5 pixels for this layout.
So far, so good… but we did not add any behaviour to the presenters. To do that we can either do it in the initializePresenters method of override the connectPresenters method. To clearly separate the intention of the methods, we favor overriding connectPresenters.
Connecting the flow
When we click on a class of the tree, we want to update the items of the methods list with the methods of the selected class. When we click on a method, we want to update the text of the code shower with the source code of the method.
When we click on the button we want several things. That is why it is better to create a separated method. First, we want to change to label to the button to alternate between “Edit” and “Read-Only”. Then, we want to change the presenter of the code shower. If the Mini Browser is on read only mode we want to have a text presenter that is not editable. And if the Mini Browser is on edit mode we want to have a code presenter that highlights the code and show the number of lines of code. But always the code shower is going to have the same text (the code of the methods).
As a last detail, because we love details, we do not want the “Untitled window” as the window title and also we want a default extent. We override initializeWindow:method.
Voilà! We have a new version minimal version of the System Browser. If we run MyMiniBrowserPresenter new openWithSpec.
Mini Browser on Read-Only mode
Mini Browser on Edit mode
With Spec we can build from simple applications to very sophisticated ones. The dynamic properties are simply nice. Spec has lots of presenters that are ready to be used. Start digging into the code to see with presenters are available, what it is their API and start experimenting and playing! Layouts can be configured in multiple ways, so have a look at their classes and the example available.
The other day we were working on the compiler detection of hotspots, originally implemented by Clément Béra during his PhD thesis. In Sista, hotspot detection is implemented as a countdown that looks like the following: the counter is loaded in a register, decremented and then a jump if carry detects if the substraction underflowed.
We were building some unit tests for this functionality, and we were interested at first at seeing how counters increment/decrement when methods execute. We wrote a couple dozen of tests for different cases (because the code for the counters is a bit more complicated, but that’s for another day). The code of one of our tests looked like the following: we compile a method, we execute it on a machine code simulator, then we verify that the counter was effectively incremented (because the public API is in terms of positive counts and not count-downs):
There was however something fishy about the ARM64 version. In addition of incrementing the counter, the code was taking the carry jump! Which lead our test to fail…
Doing some machine code debugging
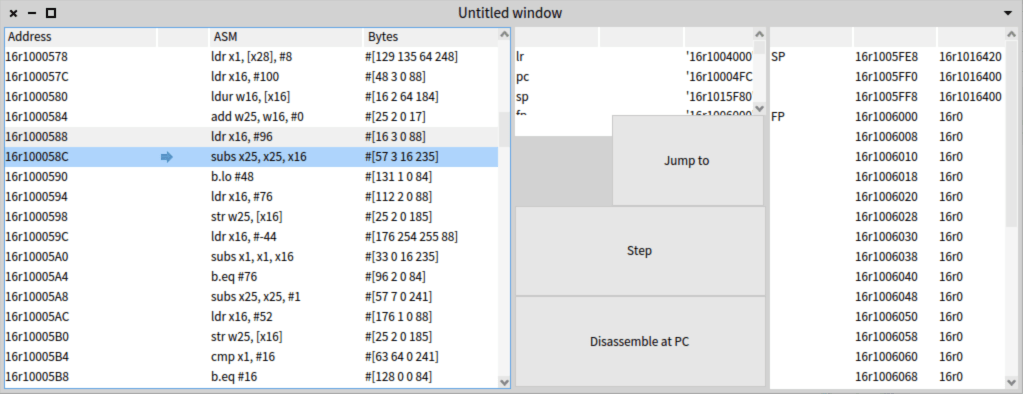
So everything was working OK on intel (IA32, X64) but not on ARM (neither 32 or 64 bits). In both ARM versions the jump was __incorrectly__ taken. I first checked the instruction was being correctly assembled. And since that seemed ok, I went on digging in our machine code debugger. I found the corresponding instruction, set the instruction pointer in there and started playing with register values to see what was happening.
As you can see in the screenshot, the code is being compiled into subs x25, x25, x16, which you can read as x25 := x25 - x16. So I started playing with the values of those two registers and the carry flag, which is the flag that activates our jump carry. The first test I did was to check 2 - 1.
self carry: false.
self x25: 2.
self x16: 1.
Substraction was correct, leaving the correct result in x25, but the carry flag was set! That was odd. So I tested a second thing: 0 - 1.
self carry: false.
self x25: 0.
self x16: 1.
In this case, the carry flag was not set, but the negative was set. Which was even more odd. The case that should set carry was not setting it, and vice-versa. It seemed it was inverted! I did a final test just to confirm my assumption: 1-1 should set both the negative and carry flags if the carry flag was inverted.
self carry: false.
self x25: 0.
self x16: 1.
ARM Carry is indeed strange
I was puzzled for a moment, and then I got to look for a culprit: was our assembler that was doing something wrong? was it a bug in Unicorn, our machine code simulator? or was is something else?
After digging for some time I came to find something interesting in the ARM documentation:
For a subtraction, including the comparison instruction CMP and the negate instructions NEGS and NGCS, C is set to 0 if the subtraction produced a borrow (that is, an unsigned underflow), and to 1 otherwise.
ARM uses an inverted carry flag for borrow (i.e. subtraction). That’s why the carry is set whenever there is no borrow and clear whenever there is. This design decision makes building an ALU slightly simpler which is why some CPUs do it.
It seems that the carry flag in ARM is set if there is no borrow, so it is indeed inverted! But it is only inverted for substractions!
Extending the Compiler with this
Since carry works different in different architectures, but only for substractions, I created a new instruction factory method JumpSubstractionCarry: that detects carry for substractions and is supposed to be platform specific. Then I replaced the code of the counter by the following:
In this article, we describe the new advanced stepping menu available in the debugger. These advanced steps provide convenient and automated debugging actions to help you debug your programs. We will see how to build and add new advanced steps, and how to extend the debugger toolbar with your own customized debugging menus.
Advanced steps
Have you noticed the bomb in the debugger toolbar? These are the advanced steps! These steps provide you with usefull and convenient debugging actions. Basically, they automatically step the execution until a given condition is satisfied. When it is the case, the execution is interrupted and its current state is shown in the debugger. In the following, we will describe these advanced steps and implement and integrate a new advanced step that skips the current expression.
Advanced steps menu in the debugger tool bar
What do these advanced steps do?
These advanced steps are a bit experimental (notice the bomb!). This means they can sometimes be a bit buggy, and in that case you should open an issue to report the bug. However most of the time, they do the job. Some of them have a failsafe that stops to give feedback to developers, in order to avoid an infinite stepping due to the impossibility to meet the expected conditions. For now, that failsafe limits the automatic stepping to 1000 steps before notifying the developer and asking if she wants to continue. The current advanced steps and what they do are describe below.
Steps until any instance of the same class of the current receiver receives a message. For instance, the receiver is a point executing the extent message. This command will step until another point receives a message.
Steps until the current receiver receives a message. For example, the next time a visitor is called back from a visited object.
Steps until the execution enters a new method. Stops just after entering that new method.
Steps the execution until the next object creation, that is, the next class instantiation.
Steps the execution until the current method is about to return. Stops just before returning.
Building a new advanced step: skipping expressions
In the following, we build a new advanced step to demonstrate how you can easily add new debugging commands to the advanced step menu.
Building the command class
First, we must create your class as a subclass of SindarinCommand. The SindarinCommand class provides small facilities to build debugger commands, such as accessors to the debugger API and to the debugger UI.
Second, we must write three class methods to configure the command: you have to provide an icon name, a description and a name. The defaultName method also contains the pragma <codeExtensionDebugCommand: 50>: this pragma is how the debugger automatically finds the command to display it in the advanced steps menu. The parameter of the pragma is the order of appearance of the menu action (we will not bother with it in this tutorial).
SindarinSkipCommand class>>defaultIconName
^#smallForward
SindarinSkipCommand class>>defaultDescription
^ 'Skips the current expression'
SindarinSkipCommand class>>defaultName
<codeExtensionDebugCommand: 50>
^ 'Skip'
If we open a new debugger, we see now that a new advanced step is available: the skip debugging action.
The new “Skip” advanced step automatically appeared in the menu.
Building the skip action
Now that we have our menu button, we need to write what it does! We must write the execute method in the SindarinSkipCommand. This method is the one called every time you click on an advanced step button.
Ideally, commands should not contains the logic of the debugging code because it requires to access and modify elements from the debugger UI (or debugger presenter) and to access and control the debugging model. This is not always possible (everything is not accessible from outside the debugger) and this also leads to complex and hard to test code in those execute methods.
That is why we provide an access to the debugger UI through the debuggerPresenter accessor, and that we only call its API in those execute commands. In our implementation below, we call the skipCurrentExpression API that implements the skipping behavior. We do not show this implementation here as our focus is the adding of new advanced steps. In addition, we prefer to create the skipCurrentExpression API as an extension method of the debugger presenter and located in the same package as our skip command class.
We see a demonstration of this new advanced step in the video below. Notice that everything is not possible: at the end, the debugger refuses to skip the return of the method.
Additionally, skipping code is a sensible operation. It can lead to an inconsistent program state, and you must use it with caution. Remember: there is a bomb in the menu 🙂
How to build your own debugger action by extending the debugger action bar
Extending the toolbar of the debugger with your own menu and commands is fairly easy. You can do it in a few steps, that we describe below.
First, we need to create an extension method of the debugger that will be automatically called by the Spec command building mechanics. This methods takes two parameters: stDebuggerInstance as the debugger instance requesting to build commands, and rootCommandGroup, the default command tree built by that debugger instance. The first instruction of this extension method is the <extensionCommands> pragma. Spec uses this pragma to find all methods extending the command tree of a given presenter (here the debugger) to automatically build extensions.
This method starts like this: StDebugger>>buildMyExtentionMenuWith: stDebuggerInstance forRoot: rootCommandGroup <extensionCommands>
Now, let us assume that you built a set of commands, that we refer to as yourCommandClasses in the following. We instantiate all your commands and store them into a commands temporary variable. Each time, we pass the debugger instance to the instantiated command. All these commands can then obtain a reference to the debugger by executing self context, which returns the debugger, and use its API.
commands := yourCommandClassescollect: [:class | class forSpecContext: stDebuggerInstance ].
The next step is to obtain the toolbar command tree from the debugger command tree. This tree contains all the default commands of the debugger, that we want to extend: toolbarGroup := rootCommandGroup / StDebuggerToolbarCommandTreeBuilder groupName.
Then, we build our own command group and we add this group to the toolbar. The following code configures that new group as a menu button that opens with a popover (as for advanced steps described above): yourToolbarGroup := CmCommandGroup forSpec beToolbarPopoverButton; name: 'Advanced Step'; icon: (stDebuggerInstance application iconNamed: #smallExpert); yourself. toolbarGroup register: yourToolbarGroup.
Finally, we register our commands to our new command group, which will make then available in the debugger toolbar: commands do: [ :c | yourToolbarGroup register: c ].
We have seen the advanced steps, what they do, and how we can build and add new advance steps. We have then see how to extend the debugger toolbar with our own customized debugger actions.
Now, you have more power over your debugger, and you can use it to build awesome debugging tools suited to your own problems!