One of the improvements that we are including in Pharo 9 is the update of the build process in OpenBuildService.
This service allows us to produce packages for different distributions of Linux. These pacakges are built using the versions loaded in the distribution and they can be installed and updated using the tools present in the system.
Currently we have support for the following set of distributions and architectures, but more are coming.
For a couple of years now, Pharo includes support for Ephemerons, originally introduced with the Spur memory manager written by Eliot Miranda. For the upcoming Pharo 9.0 release, we have stressed the implementation (with several hundred thousands Ephemerons), make it compatible with latest changes done in the old space compaction algorithm, and made it a tiny bit more robust. In other words, from Pharo 9 and on, Ephemerons will be part of the Pharo family for real, and we will work on Pharo 10 to have a nice standard library support for it. For now, the improvements are available only in the latest night build of the VM, waiting to be promoted as stable.
Still, you would be scratching your head at “what the **** are ephemerons?”. The rest of this post will give a taste of them.
What are Ephemerons?
An ephemeron is a data structure that gives some notification when an object is garbage collected, invented by Barry Hayes and published in 1997 in OOPSLA in a paper named “Ephemerons: A New Finalization Mechanism”. This mechanism is particularly useful when working, for example, with external resources such as files or sockets.
To be concrete, imagine you open a file, which yields an object having a reference to a system’s file descriptor. You read and write from it, and when you’re done, you close it. Closing the file closes the file descriptor and returns the ressource to the OS. You really want your file to be closed, otherwise nasty stuff may happen, because your OS will limit the number of files you can open.
Sometimes however, applications do not always have such a straight and simple control flow. Let’s imagine the following, not necessarily realistic, arguably not well designed, but very illustrative case: Sometimes you open a file, you pass your file as argument to some library, and… now the library owns a reference to your file. So maybe you don’t want to close it yet. And the library may not want to close it either because you are the real owner of the file!
Another possibility is to let the file be. And make sure that when the object is not used anymore and garbage collected, we close its file descriptor. An Ephemeron does exactly that! It allows us to know when an object is collected, and gives us the possibility to “finalize” it.
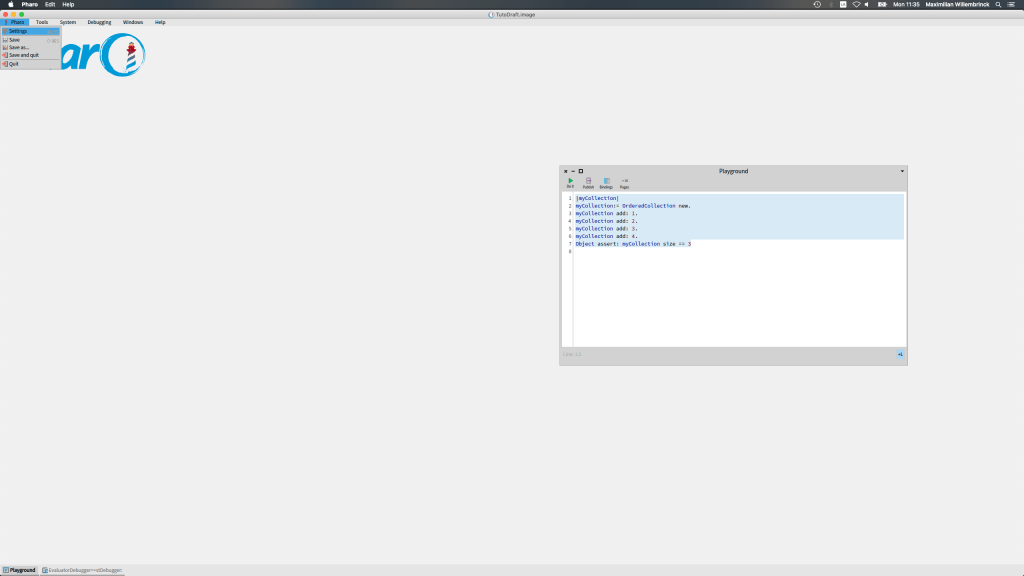
You will see that after nilling the variable obj, the Ephemeron will react and send the finalize message to our MyAnnouncingFinalizer object.
What about weak objects?
Historically Pharo also supports weak objects, and another finalization mechanism for them. A weak object is a special kind of object whose references are weak. And to say it informally, a weak reference is an object reference that is not taken seriously by the garbage collector. If the garbage collector finds that an object is only referenced by weak references, it will collect it, and replace all those weak references by a “tombstone” (which tends to be nil in many implementations).
Historically, we have used the weak mechanism for finalization in Pharo, which can be used like this:
Here, the weak array object will have a weak reference to our object, and the obj reference in the playground will be a strong reference. As soon as we nil the playground reference, the object will be detected for finalization and it will execute the finalize method too. Moreover, if we check our weak array, we will see our tombstone there in place of the original object.
obj := nil.
weakArray at: 1.
Why not using this weak finalization instead of the ephemeron one? The main explanation is performance. With the weak finalization process, every time the VM detects an object needs to be finalized, it raises an event. Then, the weak finalization library will iterate all elements in the registry checking what elements need to be finalized, by looking for the presence of tombstones. This means that for each weak object the weak finalization must do a full scan of all possible registered weaklings!
The ephemeron mechanism is more direct: when the VM detects an ephemeron needs to be finalized, it will push the ephemeron to a queue, and raise an event. Then, the ephemeron finalization will empty the queue and finalize them. No need to check all existing ephemerons.
A Weak Pharo Story, Memory Leaks and More
Of course, ephemerons are not only necessary for efficiency. They help also avoid many nasty memory leaks. A couple of years ago we did with Pavel a presentation in ESUG about a very concrete memory leak caused by mis-usage of weak objects. It’s a fun story to tell with enough perspective, but it was not a fun bug to track down at the time 😛 .
And even more, a robust ephemeron implementation will help us remove all the (potential buggy and inefficient) weak finalization code in Pharo 10!
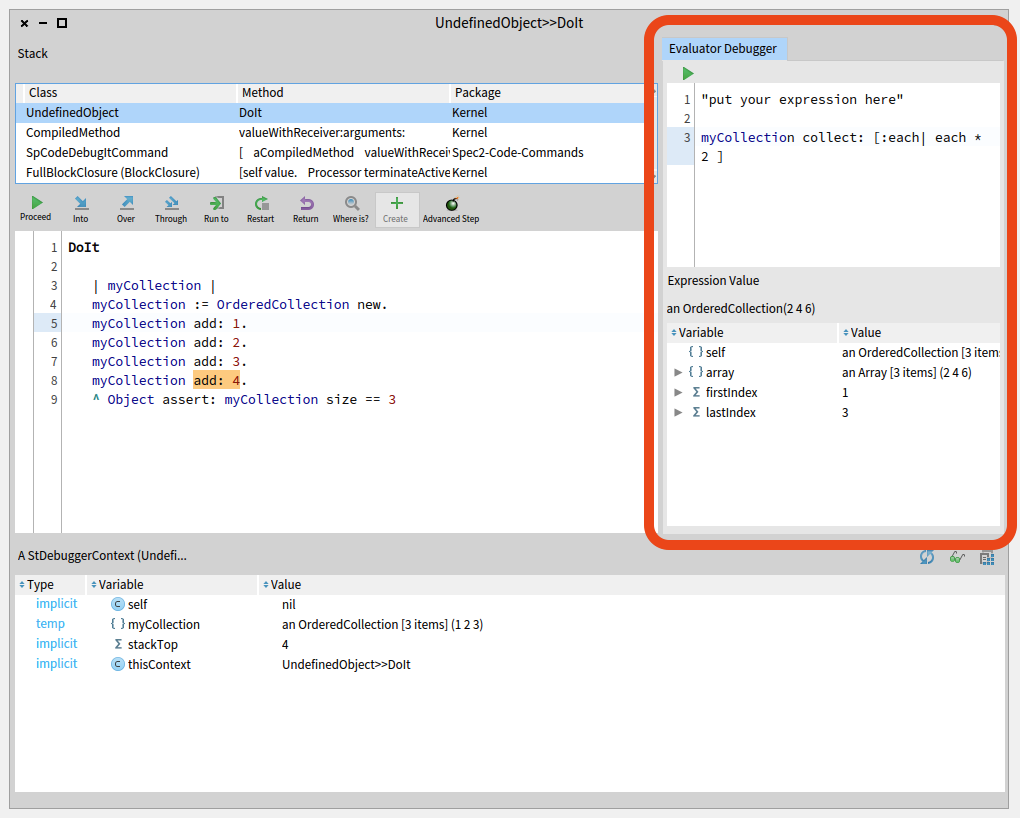
Did you ever want to get the value of an expression each time you navigate the debugger stack? This is what we will show in this tutorial: you’ll learn how to implement a new extension for the StDebugger in Pharo9.0: the ‘Expression Evaluator StDebugger Extension’ (or simply EvaluatorDebugger for short) – that allows the evaluation and inspection of an arbitrary expression in any of the available contexts.
Navigation links
I. Introduction: Outline of the debugging events and debugger extensions. II. Tutorial Part I: Creating a basic empty debugger extension. III. Tutorial Part II: Implementing an Expression Evaluator Debugger Extension.
The finished code can be found in its repository
I. Introduction
Debugging in Pharo 9.0
Whenever you debug something in Pharo, this is what happens.
Pharo choses an appropriate debugger. It’ll be the StDebugger in most scenarios.
Once a debugger is chosen by the runtime, several things happen:
The UI object for the chosen debugger is instantiated (StDebugger).
The Debug Process is started and a DebugSession object is instantiated.
An action model object (StDebuggerActionModel) is instantiated.
The associated extensions for the debugger are loaded.
The general idea is that the debugger (UI) interacts with the action model. The action model is an interface to the debug session, which owns and works over a debug process.
To understand a little bit better, here is a little explanation of each one of the actors (objects) relevant for creating a debugger extension.
I.1 StDebugger (The debugger UI)
The StDebugger class inherits from SpPresenter and acts as the main UI for the debugger. It owns the following objects:
DebugSession.
StDebuggerActionModel
The UI object it’s usually designed to allow the usage of the functionalities exposed by the ActionModel object.
I.2 DebugSession
The DebugSession models a debugging session by holding its state and providing a basic API to perform elemental debugging operations. It allows one, among others actions, to:
Step the execution.
Manipulation of Contexts.
It owns the Debug Process.
I.3 Debug Process
It’s the process that the DebugSession will work upon. It runs the debugged execution. It’s owned by the DebugSession object.
I.4 ActionModel
Your debugger extension logic should not be implemented directly in the presenter (the UI). To separate responsibilities, we code an ActionModel object, which will implement the complex execution behavior based on the Debug Session.
StDebuggerActionModel exposes all the functions that are available for the StDebugger.
I.5 StDebugger Extensions
When the StDebugger is initialized, it loads all its extensions. A debugger extension is minimally composed by the following:
A presenter object (UI). The UI, a subclass of SpPresenter, that allows the user the make use of the extensioncapabilities. Note that having just a presenter is not enough. For this object to be recognized and listed as a Debugger Extension, the class must use the Trait: TStDebuggerExtension.
An ActionModel object. This is the object that implements and exposes all its special debugging functionalities. It’s normally owned by the extension presenter.
In this tutorial, you will create a Presenter and an ActionModel for your debugger extension.
II. Tutorial – Part I
In “Tutorial Part I”, you will develop a minimal (blank, no tests, no accessors, no debugging features yet) implementation of a debugger extension, that is integrated with the Debugger Extensions system in Pharo 9.
An blank Debugger Extension is composed by an UI and an ActionModel object .
Adding a new debugger extension for the StDebugger
The first step towards a fully featured new extension is to create an empty one that is integrated with the debugger extensions system of Pharo 9, and it’s shown among the other extensions.
You will learn how to implement the following:
TheextensionUI(SpPresenter Subclass, with TStDebuggerExtension trait).
The Extension Action Model (Your actual Debugger Extensionobject that exposes its functionalities).
The finished debugger extension
Implementing the basics for debugger extensions
The Action Model
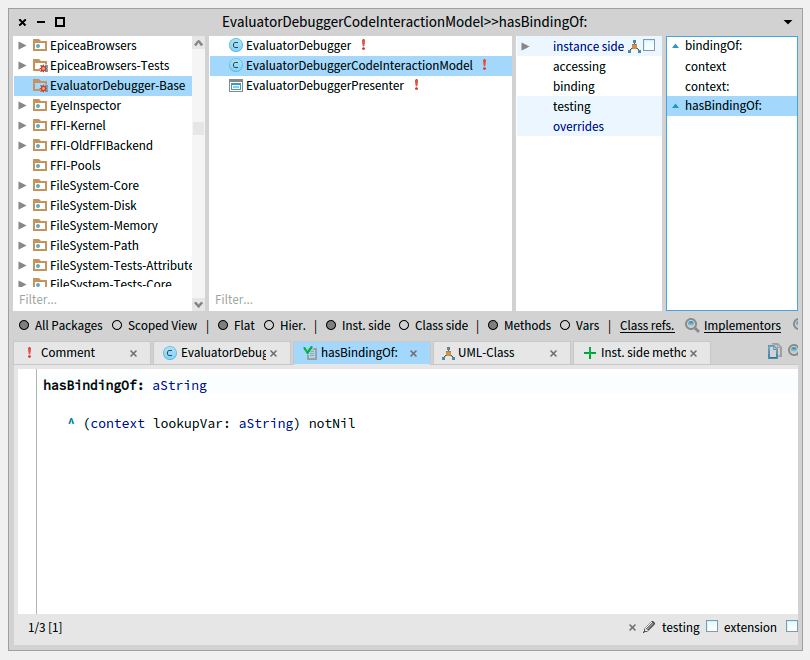
In your package of choice (Here called ‘EvaluatorDebugger-Base’), define a class for your debugger extension model. Name it “EvaluatorDebugger”. There are no constraints related to the design, but it is a good idea to hold a reference, to the StDebugger, the DebugSession, or whatever your extension might need.
Note: You are not developing a Debugger, but a Debugger Extension. Nonetheless, we call it EvaluatorDebugger for simplicity reasons.
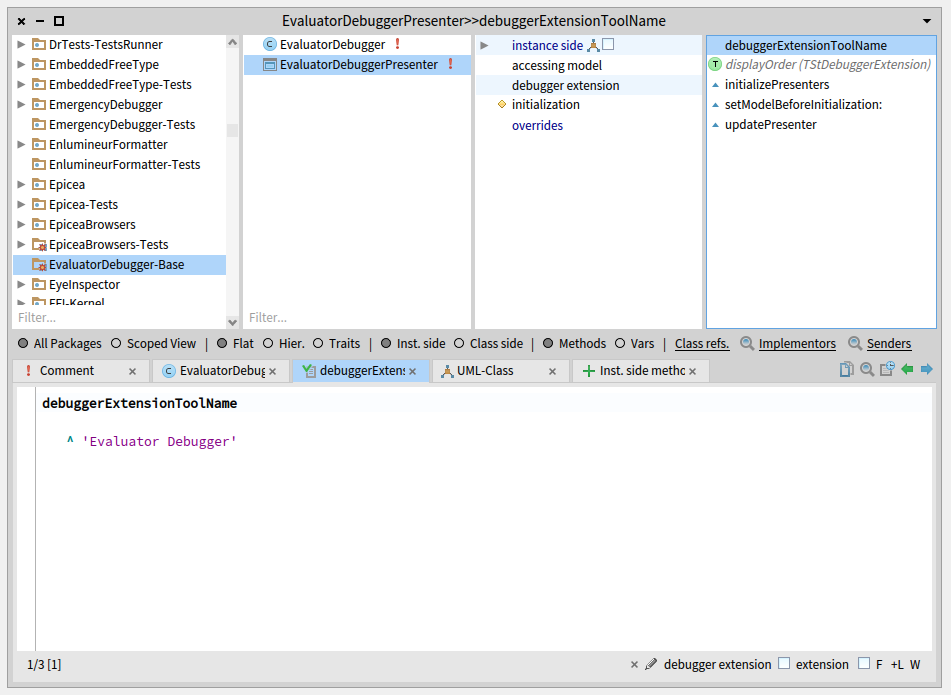
In your package of choice, create a subclass of SpPresenter that uses the trait TStDebuggerExtension. Name it “EvaluatorDebuggerPresenter”. Also, add an instance variable to hold your Action Model:
The Extensions system relies on certain methods to be implemented in your UI object to have a functional extension. Implement the following:
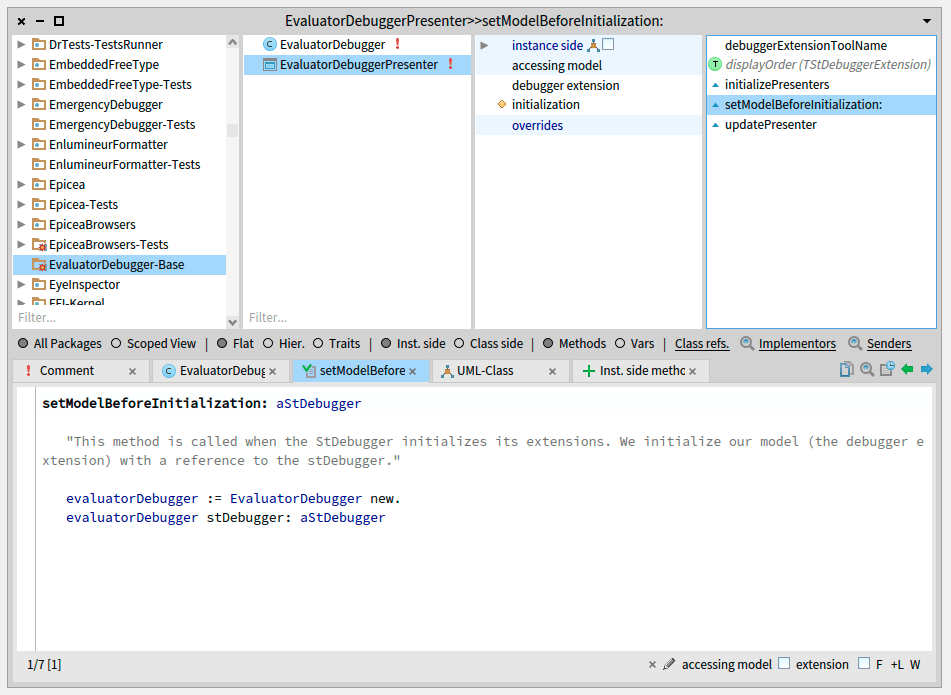
EvaluatorDebuggerPresenter >> setModelBeforeInitialization: aStDebugger
"This method is called when the StDebugger initializes its extensions.
We initialize our model (the debugger extension) with a reference to the stDebugger."
evaluatorDebugger := EvaluatorDebugger new.
evaluatorDebugger stDebugger: aStDebugger
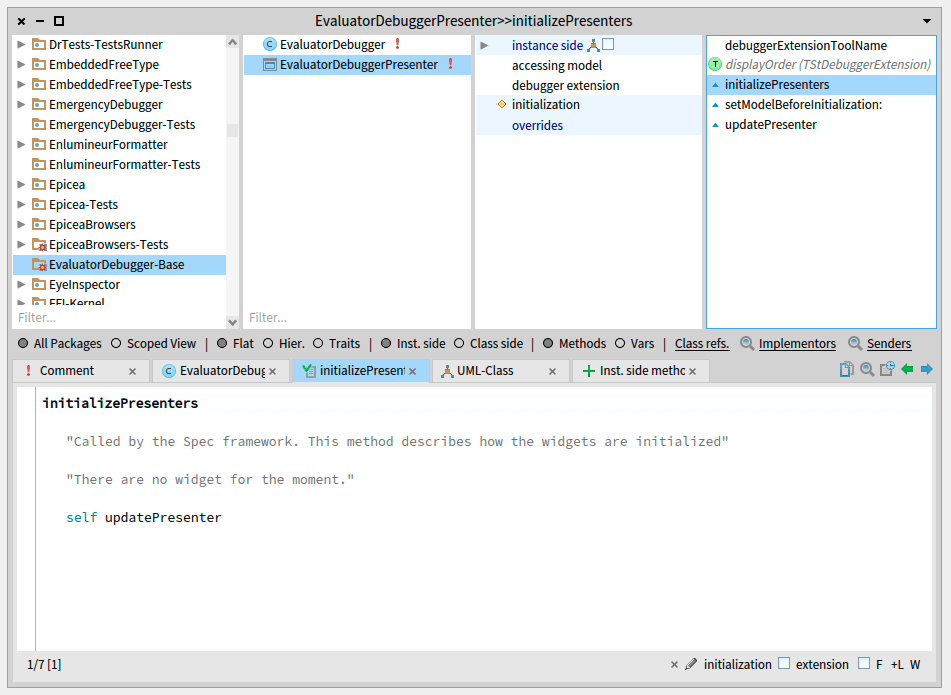
EvaluatorDebuggerPresenter >> initializePresenters
"Called automatically by the Spec framework. This method describes how the widgets are initialized"
"There are no widget for the moment."
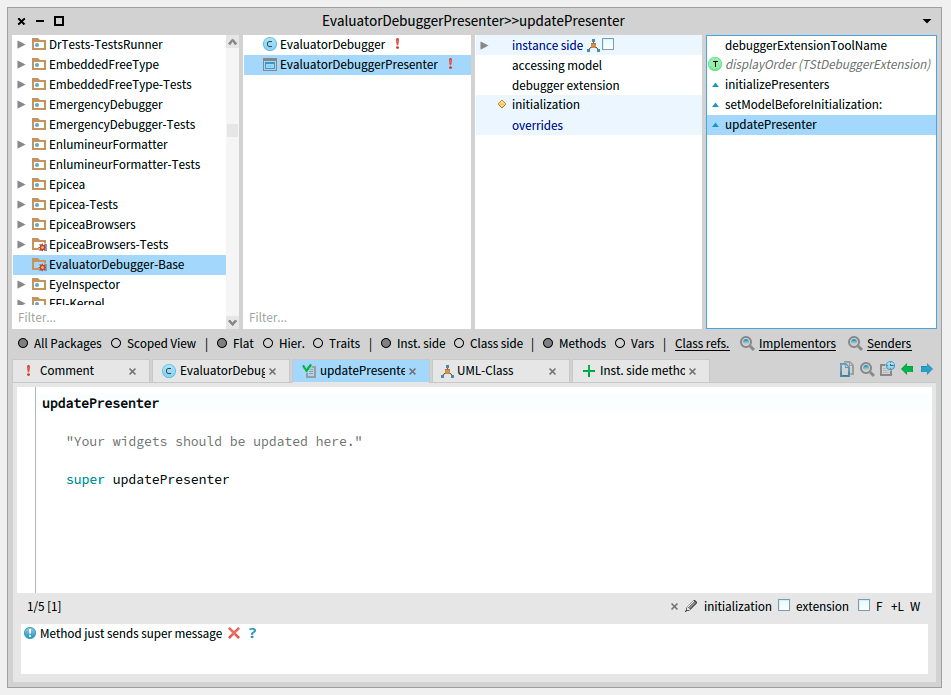
EvaluatorDebuggerPresenter >> updatePresenter
"Called automatically when the debugger updates its state after stepping"
"Your widgets should be updated here."
super updatePresenter
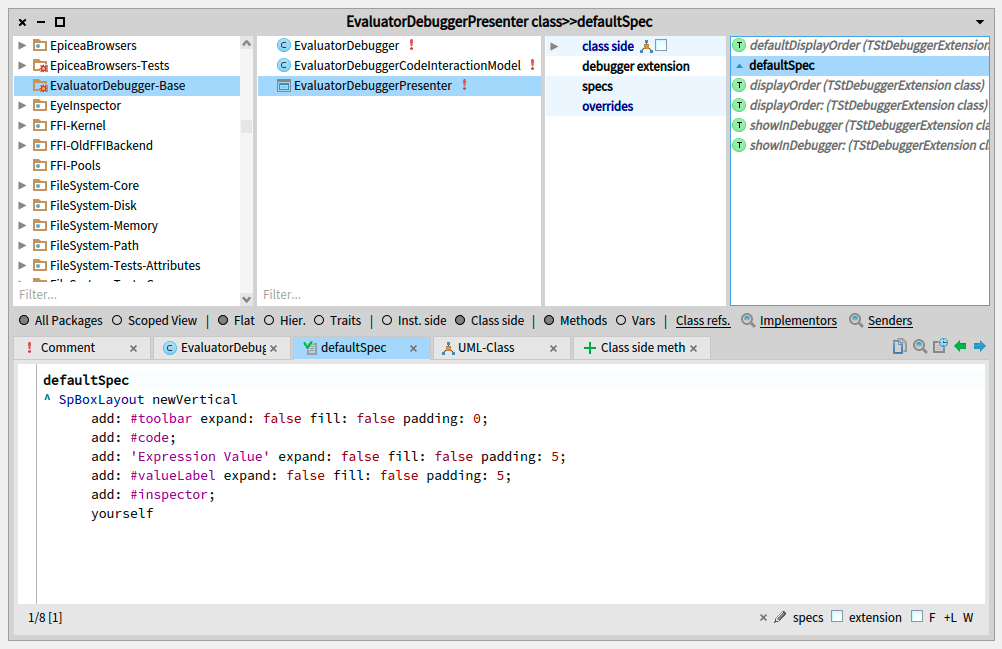
And in the class side, your presenter needs the following method to be implemented:
EvaluatorDebuggerPresenter class >> defaultSpec
"An empty vertical box layout, for the moment"
^ SpBoxLayout newVertical
So far, you have an empty debugger extension. It doesn’t do anything yet.
Next, you’ll make it appear among the other extensions.
Activate the debugger extensions in Pharo
By default, there are no debugger extension being shown.
How to see your new extension?
So far, you have a functional empty debugger extension. For it to be visible and available in the StDebugger, you need to enable the Debugger Extensions in the Pharo Settings. This is how:
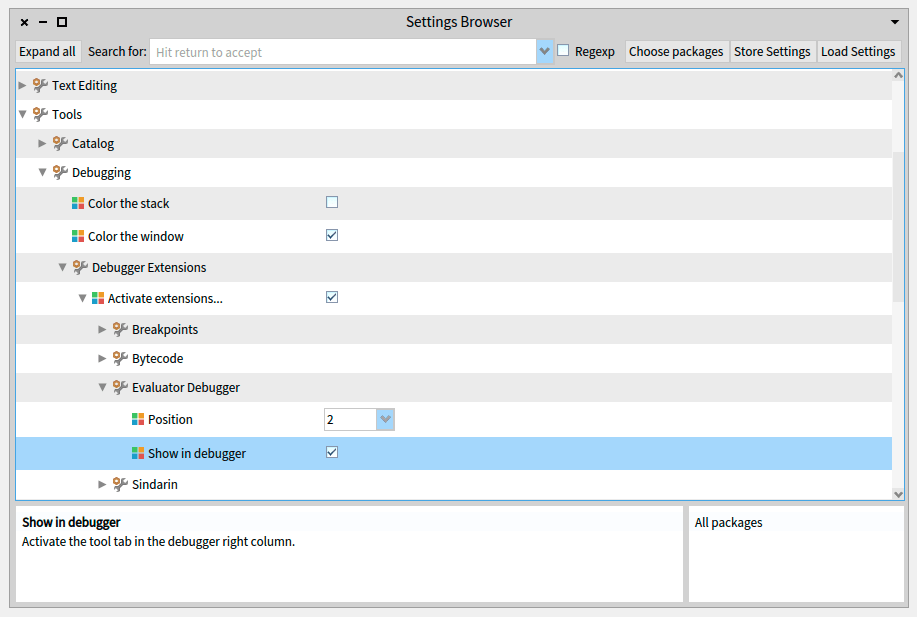
Go to the Pharo Settings.
Navigate to Tools > Debugging > Debugger Extensions and check the option Activate Extensions…
Expand Activate Extensions… and find your extension (Evaluator Debugger) check the option Show in Debugger.
Pharo > Settings in the menu bar.
Check the options to enable extension
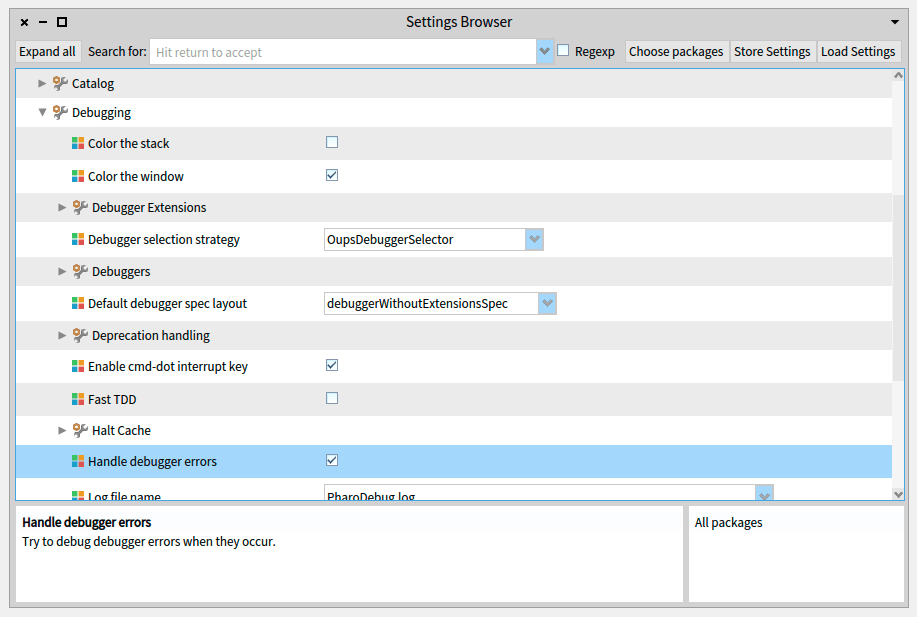
Handle Debugger Errors
Additionally When developing debugger extensions, it is recommended to enable the option to Handle Debugger Errors, like in the last picture.
By default, if your debugger extension throws an error, it will be ignored and the StDebugger will not load the extension. This means that you can’t debug your extension code directly in case of failure. By enabling Handle Debugger Errors, whenever an error is thrown in your extension, a new StDebugger(without extensions) instance will be launched so you can debug it.
For this, navigate and check the option: Tools > Debugging > Handle Debugger Errors.
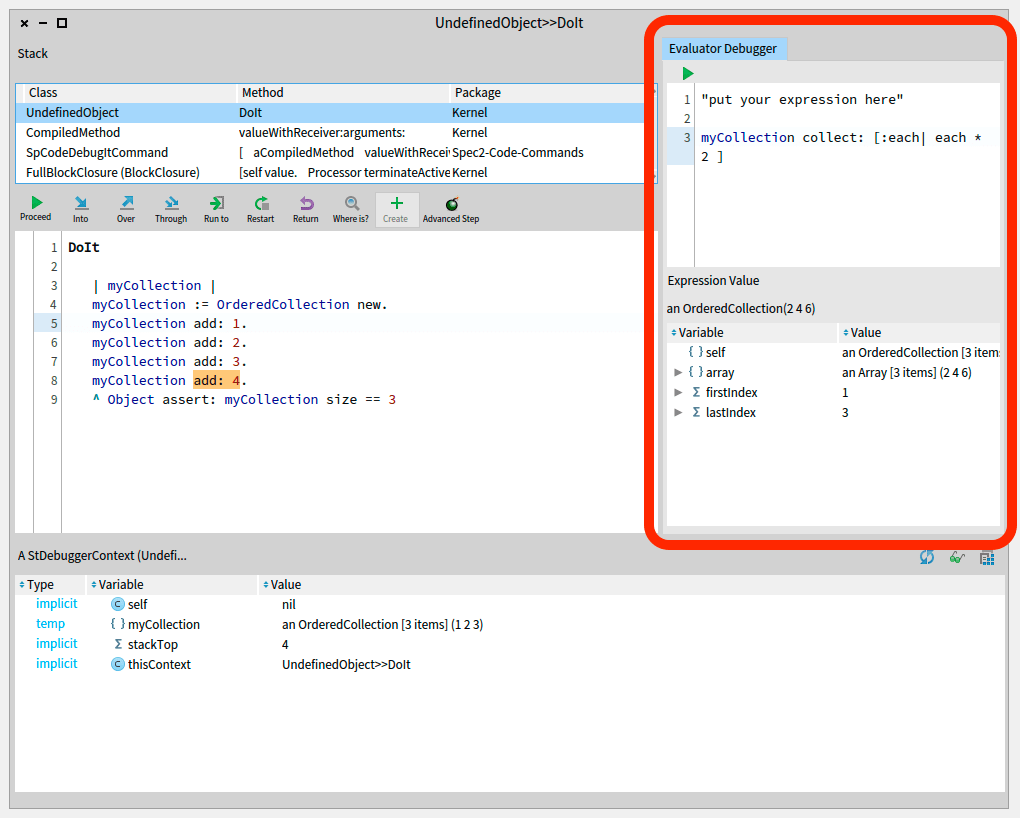
From now on, whenever you debug something, your extension should appear in the top-right pane.
Your empty debugger extension, shown in the StDebugger
III. Tutorial – Part II
Implementing the Expression Evaluator StDebugger Extension
Remember: For readability purposes, in this tutorial the extension is called simply by “EvaluatorDebugger” instead of its full connotation: “Expression Evaluator StDebugger Extension”
Now you’ll add your extension functionalities. For this, you will:
Implement the logic of your debugger extension (Implement the ActionModel – EvaluatorDebugger – methods).
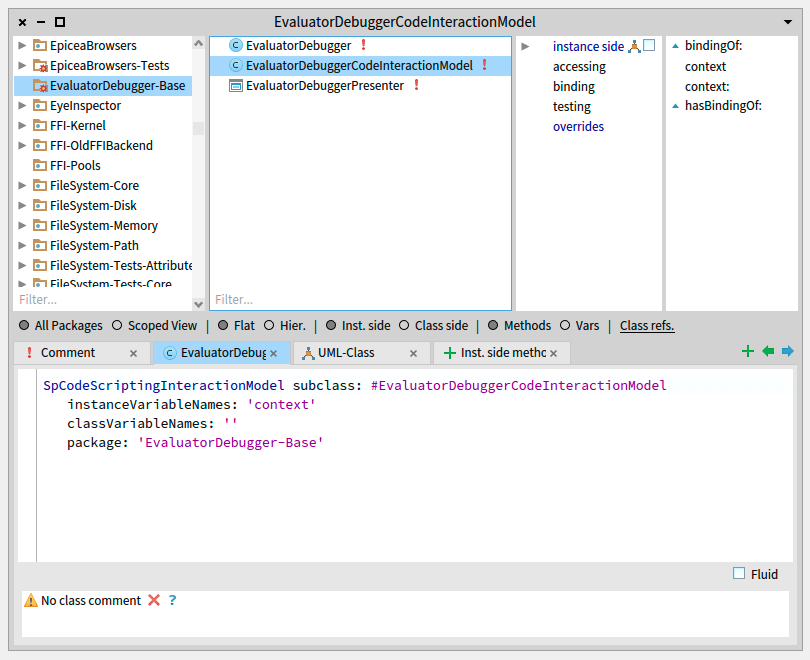
Implement an object subclass of SpCodeScriptingInteractionModel – EvaluatorDebuggerCodeInteractionModel – needed for the expression-evaluation-in-context logic.
Finish the UI (EvaluatorDebuggerPresenter) layout and widgets.
EvaluatorDebugger
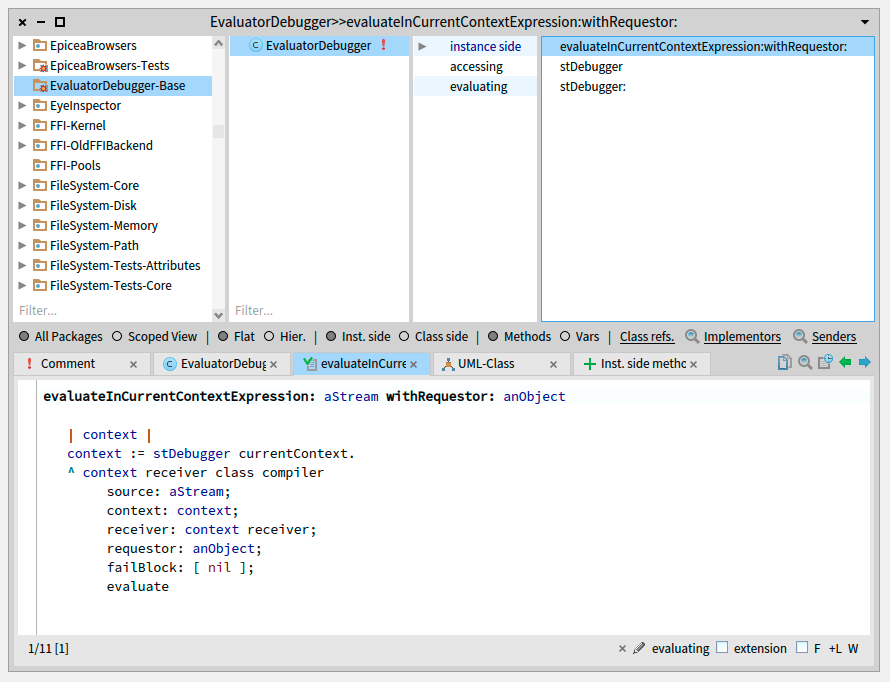
During the Tutorial – Part I, we developed an Action Model without any behavior – The EvaluatorDebugger. This time, we will complete the class with the intended logic by adding a method that allows the evaluation of an expression in a given Context.
Add a new method: #evaluateInCurrentContextExpression:withRequestor:
EvaluatorDebugger >> evaluateInCurrentContextExpression: aStream withRequestor: anObject
"Evaluates the expression coming from a stream. Uses the current context of the StDebugger"
| context |
context := stDebugger currentContext.
^ context receiver class compiler
source: aStream;
context: context;
receiver: context receiver;
requestor: anObject;
failBlock: [ nil ];
evaluate
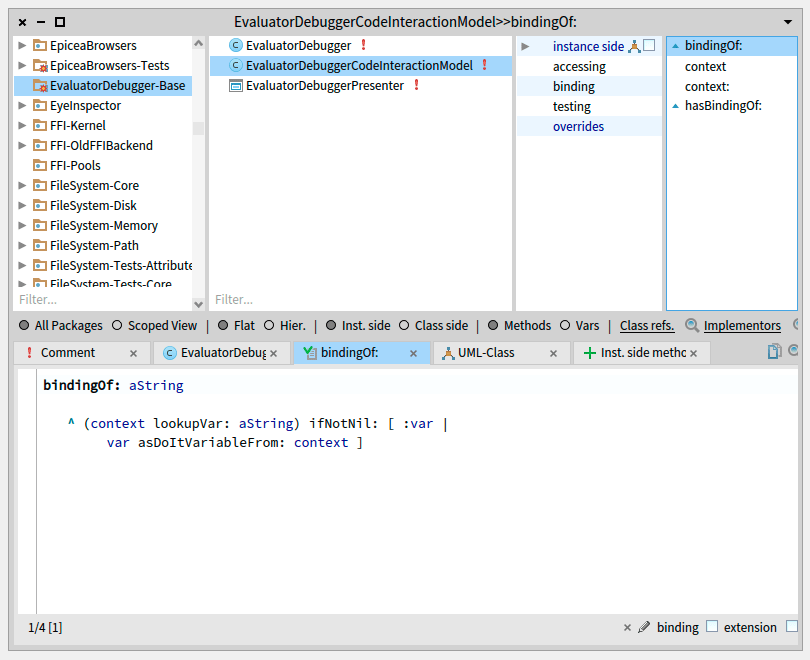
EvaluatorDebuggerCodeInteractionModel
Your extension UI will feature a SpCodePresenter, where the user can type an expression which is evaluated in the selected context of the StDebugger.
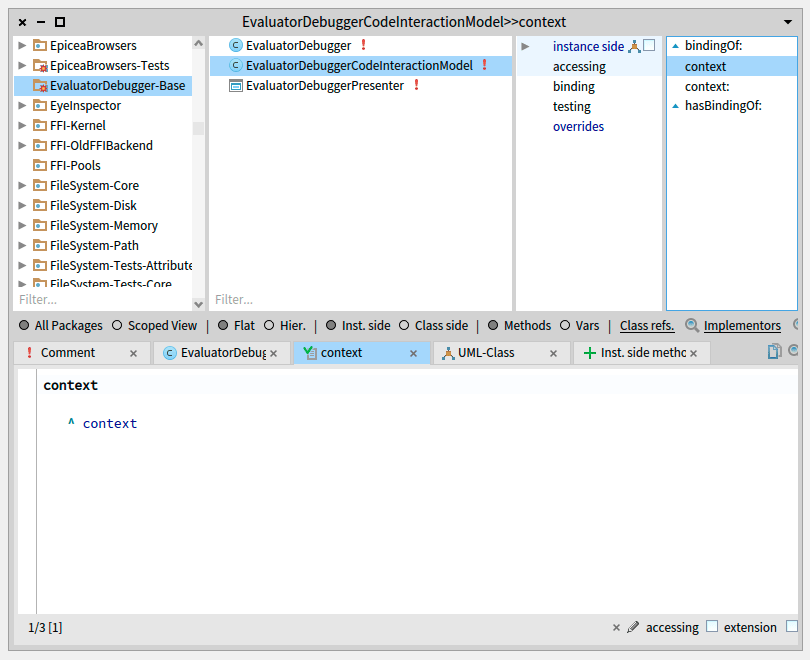
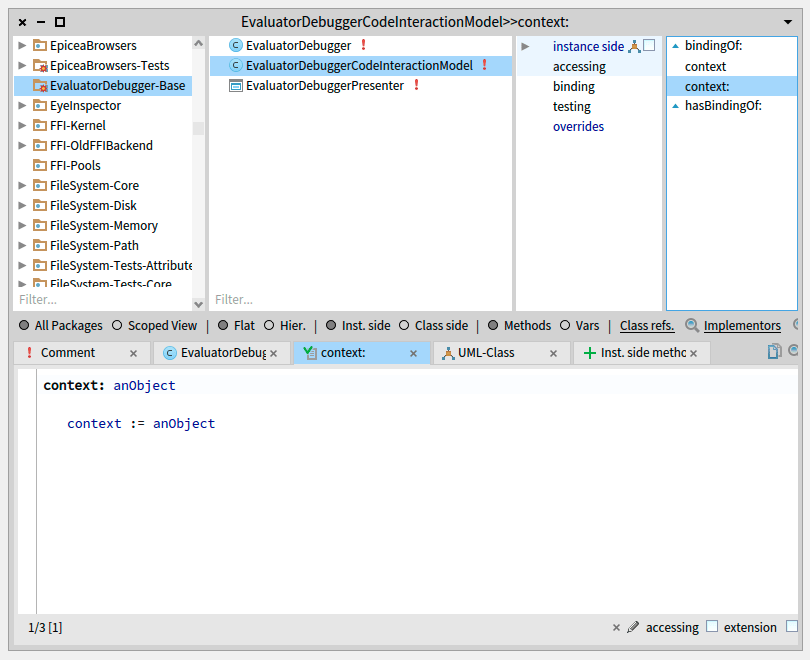
Your code presenter should consider the current selected context to correctly work with your code (Syntax highlighting, inspection, etc), and for this you need to implement a subclass of SpCodeScriptingInteractionModel as follows.
EvaluatorDebuggerPresenter >> initializeCode
"We define the extensions Code presenter initialization here"
code := self newCode.
code interactionModel: EvaluatorDebuggerCodeInteractionModel new.
code syntaxHighlight: true.
code text: '"put your expression here"'
EvaluatorDebuggerPresenter >> initializePresenters
"Called by the Spec framework. This method describes how the widgets are initialized"
self initializeToolbar.
self initializeCode.
valueLabel := self newLabel.
valueLabel label: 'Write an expression first'.
inspector := nil inspectionRaw.
inspector owner: self.
"when changing the selected context in the stDebugger stackTable, re-evaluate the expression in that context"
evaluatorDebugger stDebugger stackTable selection whenChangedDo: [
self updatePresenter ].
self updatePresenter
EvaluatorDebuggerPresenter >> initializeToolbar
toolbar := self newToolbar
addItem: (self newToolbarButton
icon: (self application iconNamed: #smallDoIt);
action: [ self updatePresenter ];
yourself);
yourself
Note:
‘updatePresenter’ is meant to be automatically called when the debugger updates its state after stepping, and changing the context in the stack. However, the current version of Pharo9.0 – at the date of writing 2021/02/16 – doesn’t perform the update after changing the selected context. To fix this, we used the following “hacky” code:
and add an updatePresenter call to the table selection changecallbacks collection in the method initializePresenters above.
Behavior
The user will write expressions and “press buttons/click things” in the debugger and your extension, expecting something to happen. Also, the StDebugger might issue an “updatePresenter” call to all the extensions. You need to code that.
Add an accessor to directly expose the current context.
EvaluatorDebuggerPresenter >> currentStDebuggerContext
"A 'shortcut' to get the same currentContext of the StDebugger"
^ evaluatorDebugger stDebugger currentContext
Remember that whenever the StDebbuger updates its state, it will automatically call updatePresenter for each of the extensions. We want the code presenter to reflect that, and also the displayed expression value.
EvaluatorDebuggerPresenter >> updatePresenter
"Called automatically when the debugger updates its state after stepping"
self updateCode.
self updateExpressionValueDisplayed.
super updatePresenter
EvaluatorDebuggerPresenter >> updateCode
"Sets the context of our debugger-extension code presenter to be the same one of the StDebugger"
code interactionModel context: self currentStDebuggerContext
EvaluatorDebuggerPresenter >> updateExpressionValueDisplayed
"Evaluate the expression, in the code presenter, using the appropriate context (the current one of the stDebgger). Then update the ui to show and inspect the obtained value, or a potential exception."
| expressionBlock expressionResult errorFlag errorMessage |
expressionBlock := [
evaluatorDebugger
evaluateInCurrentContextExpression:
code text readStream
withRequestor: code interactionModel ].
errorFlag := false.
expressionResult := expressionBlock
on: Exception
do: [ :e |
errorFlag := true.
errorMessage := e description.
e ].
"The inspector shows the result object in case of success, or the Exception otherwise"
inspector model: expressionResult.
valueLabel label: (errorFlag
ifTrue: [ errorMessage ]
ifFalse: [ expressionResult asString ])
Try it!
Now you have a fully functional debugger-extension. Try debugging some code!
Write an expression in your extension’s code presenter (try the code in the image below, if following the example).
Select different Contexts in the stDebugger and see what happens!
Conclusion
The Pharo 9.0 debugger extensions system allows one to conveniently add new ones. The example developed in the tutorial explores all the basic aspects needed to have a functional extension completely integrated with the environment. Should you need to create a new one, or modify and existing one, now you have the knowledge.
Docker is an excellent tool to manage containers, and execute applications on them. This is not a discovery!! The idea of this post is to show how easy and simple is to have a Pharo 9 Seaside application running in Docker.
Initial Considerations
This post is based in the excellent Docker image written by the Buenos Aires Smalltalk group (https://github.com/ba-st). They maintain a repository with configurations for different Docker images from Pharo 6.1 to Pharo 9.
These images are also available from Dockerhub (https://hub.docker.com/r/basmalltalk/pharo), so you can choose also to download the images ready from there. As we are going to do in this small example.
Also, to complete this example we are using an existing Seaside application. We are using the example of TinyBlog. This is an excellent tool to learn Seaside, Voyage and Pharo in general. It is available here.
In order to start a container with our application, we need to create an image with all the requirements installed and built. Once we have it, it is possible to start one or more instances of this application.
For doing so, we are going to start from the image from basmalltalk/pharo:9.0-image.
We need to pull this image from Dockerhub so it is available for us to use, we execute so:
docker pull basmalltalk/pharo:9.0-image
Once we have the initial image, we need to give a Dockerfile with the recipe to build our application image. The downloaded image already come with a Pharo9 VM and image. We need to perform the following steps on this image:
Install our application with all the dependencies using Metacello
Generate the initial test data of the application
Define an entry point that will execute the Zinc server
Expose the Zinc server port so it can be used outside the container
For doing so, we are going to create a file called Dockerfile with the following content:
FROM basmalltalk/pharo:9.0-image RUN ./pharo Pharo.image eval --save "Metacello new \ baseline:'TinyBlog'; \ repository: 'github://LucFabresse/TinyBlog/src'; \ onConflict: [ :ex | ex useLoaded ]; \ load" RUN ./pharo Pharo.image eval --save "TBBlog reset ; createDemoPosts" EXPOSE 8080/tcp CMD ./pharo Pharo.image eval --no-quit "ZnZincServerAdaptor startOn: 8080"
Once we have a Dockerfile stored, you can put wherever you like it. It is time to build an image using it. We need to be in the directory next to the Dockerfile and execute:
docker build -t pharo/tinyblog:latest .
This will create a Docker Image using the description of the Dockerfile in the current directory, and the new image will be called pharo/tinyblog with a tag marking it as latest.
Once the process is finished, if we list the images with
docker images
We get:
REPOSITORY TAG IMAGE ID CREATED SIZE
pharo/tinyblog latest fee45c26e604 56 minutes ago 727MB
Executing Our Application
Once we have an image of our application, it is possible to execute this image as one or more containers. We are going to execute a container with the image, and we are going to redirect the port 8080 to the outside; so we can access it.
For doing so, we execute:
docker run -d -P pharo/tinyblog
This will execute our image pharo/tinyblog in detached mode (-d), so it will run in the background, and publishing all ports to the outside (-P). The command will return the ID of the container.
This is a really simple example of running an application, as this is not a Docker tutorial we are only to show a little simple example.
If we check the running containers with:
docker ps
We can see the information about the running containers
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3191540dbeb3 pharo/tinyblog "/bin/sh -c './pharo…" 44 minutes ago Up 44 minutes 0.0.0.0:32768->8080/tcp fervent_goldstine
We can see that our application is running , and that the redirected por is 32768. Also, we can see some statistics about the image and the ID and a fantasy name, we can use any of them to refer it in any docker command like stop, rm, etc.
Once, we have our container we can do any other thing that we can with containers. From stopping it, resuming it, using it in collaboration with other containers or in a multi container infrastructure. But that…. is for other story.
Conclusion
This small post is just to show how the different tools and technologies of Pharo can easily be integrated with state-of-the-art solutions. If it is interest to the community, this post can be the start of nice infrastructure serie.
This post is now out-dated. The current version is available in Pharo Zero-Conf, and in the future in the Pharo Launcher.
Check https://get.pharo.org/
After receiving the new Apple Mini with the M1 processor, we are producing the first version of the Pharo VM. This version, is a base version that lacks JIT optimizations and requires external libraries (it is not build as a bundle). However, it is a good step forward to have a working version in this new combination of architecture and OS. Also, this VM, even without JIT, has better performance than the VM with JIT using Rosetta 2.
We are going to start soon the final stroke in the development of the new version including the JIT, as mostly of it reuses the one already done for Linux ARM64 and Windows ARM64. The required changes are linked with changes done by Apple in the Operating System API, and some “Security improvements” of the new OS.
Requirements
In this first version, it is required to have installed some libraries with Brew (https://brew.sh/). These requirements will be removed in next versions.
The packages to install are:
cairo
freetype
sdl2
libgit2
Linking LibGit2
Pharo 9 is expecting to use LibGit2 1.0.1 or 0.25, but Brew includes the version 1.1.0. To fix this problem we can link the version 1.1.0 as 1.01. This is a temporal hack as the correct version will be shipped in a release of the VM.
For doing so, we need to execute:
cd /opt/homebrew/lib
ln -s libgit2.1.1.0.dylib libgit2.1.0.0.dylib
If you have a Windows ARM64 machine such as the Surface Pro X, chances are you may want to debug native ARM64 applications with it. However, as of today 2/12/2020, Windows does not support local debugging of ARM64 applications, but only remote debugging. Moreover, CMake projects cannot be configured to use remote debugging, or I did not find it after hours of searching and googling :).
This page covers how to debug the CMake project of the VM on ARM64 using the Windows remote debugger and Visual studio. The remote debugger can be used from a separate machine, or from the same machine too, giving mostly the impression of a local debugger. Yet, there are some glitches and remaining problems.
Installing the Windows Remote Debugger on the ARM64 Machine
The first thing to do is to install the Windows Remote Debugger application on the target machine, the machine we want to debug on. The instructions are in here.
Basically, just install the remote tools package, and open it a first time to set up the network configuration. Make sure you go to the options and you check the port of the connection or set it to the port of your preference
Getting rid of CMake-VS integration (?)
Visual Studio CMake integration is nice, though it does not support our debugging use case. Visual Studio CMake integration so far lacks proper support for ARM64 configurations, and most of the debugging options and features one can set from a normal project. So, instead of opening a CMake-tailored Visual Studio project, we are going to create a normal Visual Studio solution from the command line, and then open it as a normal solution.
To manually create it run the following, specifying your own configuration arguments. Notice that this post was only tested in Visual Studio 2019.
$ cmake -B ARM64Solution -S ../repo -G "Visual Studio 16 2019" -A ARM64
Notice that the solution we did create will not contain the Slang-generated source files of the VM. If you want to generate them, you may run from the command line the following, which we support for now only on x86_64 machines.
Otherwise, copy them from some previous generation if you already have them, as I do, and use the following command to create your project instead (you may want to look at the full set of options in here):
$ cmake -B ARM64Solution -S ../repo -G "Visual Studio 16 2019" -A ARM64 -DGENERATE_SOURCES=FALSE
Now you will see CMake has created a lot of .sln and .vcxproj files. Open the solution using Visual Studio: Done! You’re almost there!
Configuring the Project for debugging
The basic information to debug the VM using this setup is now the one described in here: how to remote debug c++ apps. Basically this can be resumed in two steps: 1) configure debugging to use remote debugging on localhost:ourPort and 2) set up deployment of binaries.
Step 1, configure debugging to use remote, can be easily done as specified in the link above: right click on the project, debugging, turn on remote debugging, configure the fields as in the link.
Step 2, set up deployment of binaries, is required because otherwise the debugging runtime seems to not be available by default in the machine. Deployment takes care of deploying the windows debugging runtime too.
Finally, an extra problem I’ve found was that CMake creates some extra targets/projects ALL_BUILD and ZERO_CHECK that cannot be properly deployed. I removed them from the solution and everything worked like a charm.
Now clicking on the run/debug button will compile, “remotely” deploy, launch, and connect to the VM, and you’ll be debugging it natively in ARM64!
To finish, some caveats
For starters, all this dance between CMake and Visual Studio makes it difficult to find proper information online. What is clear is that CMake has far more features than what Visual Studio supports from it: for example, we cannot build our CMake project from Visual Studio on ARM64 yet without doing some manual mangling as the one in this post.
Also, manually removing the ALL_BUILD and ZERO_CHECK projects to debug does not seem the very best solution, I’d like to have something more straight forward that works by default.
Let’s hope that VS CMake integration and support for ARM64 local debugging comes soon.
Today, some Pharo users asked why we have lost a nice feature in Mac OS X. In this operating system, it is possible to Cmd-Click on the title of a window, if the window represents an open document, a nice menu showing all the path to it appears. Also, the user can select to open Finder (the file explorer) in any of this directory.
Menu that Appear with CMD+Click on the title of a window
This feature was not available anymore in the latest Pharo 9 VM. What happened? Does the VM has a regression? Do we need to throw everything away and use another programming language :)? Let’s see that this is not the case. And also, it is a nice story of why we want the in-image development in the center of our life.
Where is the Window handled?
One of the main features introduced in the VM for Pharo 9 is that all the handling of the events and UI is done in the image side. The so called “headless” VM has no responsibility in how the world is presented to the user.
When the image starts, it detects if it is running in the “headless” VM. If it is the case, it knows it should take the responsibility to show a window to the user. Also, the image is now able to decide if we want to show a window or not and what kind of window we want. In this case, we want to show the Morphic-based world.
To handle the events, render and show a window, the image uses SDL as its backend. This is one of the possible backends to use, but we are not going to talk about other than SDL in this article. The creation of the window and its events is done through the OSWindow package, if you want to see it.
SDL provides a portable way of implementing a UI in a lot of different architectures and operating systems. Allowing us to use the same code in all of them. Also, the image is using the FFI bridge that does not present a major slowdown for managing events and redrawing.
But.. why is this important or better?
One of the key points is portability, so the same code can be executed in different platforms, but it is not the only one. Also, it allows the image to decide how to handle the UI. Doing so, it allows applications built on top of Pharo to create the UI experience they desire.
A final benefit, that in this case is more relevant for us, is the flexibility to modify it from the image, and to do it in a live programming fashion.
We think all these points give more ability to the users to invent their own future.
Solving the Issue
This issue is a simple one to resolve. We need to only take the Cocoa window (the backend used by all OSX applications) and send the message setTitleWithRepresentedFilename:, something like the following code will do the magic.
We want it portable: we want the issue fix, but we want all the other platforms to continue working also.
Let’s solve all the problems from our nice lovely image.
Accessing the Window
The first point is easy to solve. SDL and the Pharo bindings expose a way of accessing the handler of the real Cocoa window that SDL is using. SDL exposes all the inner details of a window through the WMInfo struct.
The Cocoa Framework exposes all its API though the use of ObjectiveC or Swift. None of them we can use directly. Fortunately, there is a C bridge to communicate to the ObjectiveC objects. It is exposed through a series of C functions. And, we can use the Unified-FFI support of Pharo to call these functions without any problem. Here it is the description of this API.
We can use a wrapper of these functions that has been developed for Pharo: estebanlm/objcbridge. However, we only need to call a single message. So, let’s see if we can simplify it. We don’t want to have the whole project just for doing a single call. If you are interesting of a further implementation or using more Cocoa APIs, this a good project to check and it will ease your life.
As we want a reduced version of it, we are going to use just three functions, with its corresponding use through Unified FFI:
SDLOSXPlatform >> sendMessage: sel to: rcv with: aParam
^ self ffiCall: #(void* objc_msgSend(void* rcv, void* sel, void* aParam))
The first two functions allows us to resolve an Objective C class and a selector to call. The third one allows us to send a message with a parameter.
As the parameter to the function “setTitleWithRepresentedFilename:” is expecting a NSString (a String in Objective-C), we need to create it with our utf-8 characters. So we have the following helper:
aParam := self nsStringOf: aString.
wmInfo := aOSSDLWindow backendWindow getWMInfo.
cocoaWindow := wmInfo info cocoa window.
selector := self lookupSelector: 'setTitleWithRepresentedFilename:'.
self sendMessage: selector to: cocoaWindow getHandle with: aParam.
self release: aParam. "It sends the message #release to the objective-C object, important for the reference counting used by Obj-C"
Doing it portable
Of course this feature is heavy related with the current OS. If we are not in OSX, all this code should not be executed. To do so, the best alternative is to have a strategy per platform. This idea may look an overkill but it allows us better modularization and extension points for the future.
Also, it is a good moment to implement in the same way some specific code for OSX that was using an if clause to see if it was in OSX.
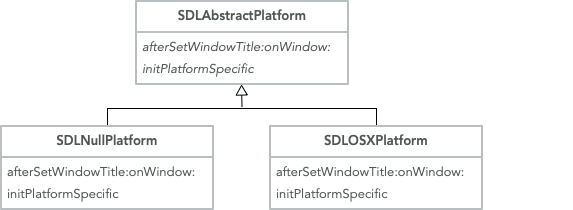
So, the following strategy by platform is implemented:
In the strategy, there is a Null implementation that does nothing. This is used by all other operating systems, and an implementation that is used by OSX. This implementation for OSX has all the custom code needed to change the file associated with the window.
This strategy is then accessed through extension methods in the OSPlatform subclasses. One important point is to do this through extension methods, as we don’t want to introduce a dependency from OSPlatform to SDL.
For the OSX platform:
MacOSXPlatform >> sdlPlatform
^ SDLOSXPlatform new
For the others:
sdlPlatform
^ SDLNullPlatform new
Conclusion
Presenting the solution to this issue was a good excuse to present the following points:
How to introduce platform dependent code without bloating the system with Ifs.
How to interact with the operating system through FFI.
How we can take advantage of the image controlling the event handling and the UI.
We consider these points very important to allow developers to create portable and customizable applications while taking full advantage of the programming capabilities of Pharo.
From time to time it happens that a bug is accidentally introduced and we realize it several versions later. If the cause of the bug is not clear, one good strategy is to find the piece of code change that introduced the bug, and engineer a test and fix from that change. If we have the entire history of changes of the project, we can then extract this information from the commits.
In this post, we will show how we can apply a bisection of Pharo builds easily using the Pharo Launcher to find the cause of a bug. In particular, I wanted to show the case of a real bug, from which you’ll find the issue here https://github.com/pharo-project/pharo/issues/6012: the code completion menu was not being closed when clicking outside of it.
There is git bisect…
Git provides a pretty useful command called git bisect that helps you at finding the culprit commit. Git bisect implements a binary search on commits: it proposes you commits that you have to test and mark as good or bad. Based on how you tag a commit it will look for another commit and eventually find you the exact commit that introduced the problem.
Git bisect can be pretty handy at finding bugs, but it can be pretty heavy when on each step you need to do a long build process just to test it. This is exactly our case when bisecting the pharo history: we need to build an image.
We are not going to go into much details with git bisect, but if you want to see some more docs on it, you can take a look at the official docs in here: https://git-scm.com/docs/git-bisect.
Image bisection with the Pharo launcher
The Pharo launcher has a super fancy feature that can be used for bisection: it allows downloading any previous build of Pharo that is stored in the Pharo file server. This saves us from building an image for each version we are digging in! It is important to know at this point that the Pharo file server stores all succeeding builds of Pharo, which are almost all of them, and that there is a build per PR. So this will save us some time at attacking the issue but it will be a bit less precise because a PR can contain many commits. However, once the PR is identified, in general the commits in it will be all related.
In the Pharo9.0 template category we have listed all its builds with number and associated commit
Once we know this we can do the bisect ourselves. For example, if we want to test the entire set of 748 builds, we will first test 748 / 2 = build #374. If it is broken, it means that the problem was introduced in between builds #1 and #374, and we need to continue testing with 374 / 2 = build #187. Otherwise the bug was introduced between build #374 and build #748 and we should test with 748 + 374 / 2 = build #561. We can continue like that until we find the build X where X is working and X+1 is broken.
The advantage of doing it as a binary search comes from the fact that we cut the space search by 2 every time. This makes the search a log2 operation. In practical terms: if we have 1000 commits, we will have to do log2 1000 = ~10 searches to find the culprit. Which is far better than linearly searching the 1000 commits one by one :).
Finding the problematic PR
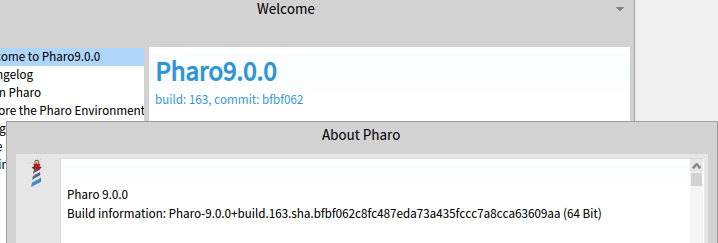
The issue we were interested in did not exist on build #162 and it stopped working in build #163. The next step is to understand what was introduced in build #163. Once we have the breaking build, we need to obtain the PR that lead to the change. We can obtain the PR commit from the image file name given by the launcher, or we can get it from the about and help dialogs in Pharo.
The about and help dialogs have precise information of how the image was built.
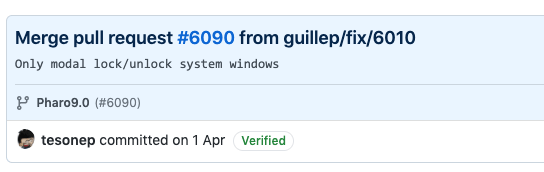
Once we have the commit, the next step is to look for it in git in your favorite tool: the command line, iceberg, any external GUI based git tool, or even github. Since there are no integrations in Pharo that are not pull requests, each build commit will effectively be a PR merge commit. In our real bug example, the problematic commit was this one, which was the integration of a PR I did myself ( 🙂 ).
The problematic commit is always a PR integration in Pharo
Now that we have the problem, we can engineer a fix for it.
Analyzing the bug
So again, this was working on build #162. It stopped working with my changes in #163. To understand the issue my strategy was the following: compare how the execution flows in both the working and non working builds.
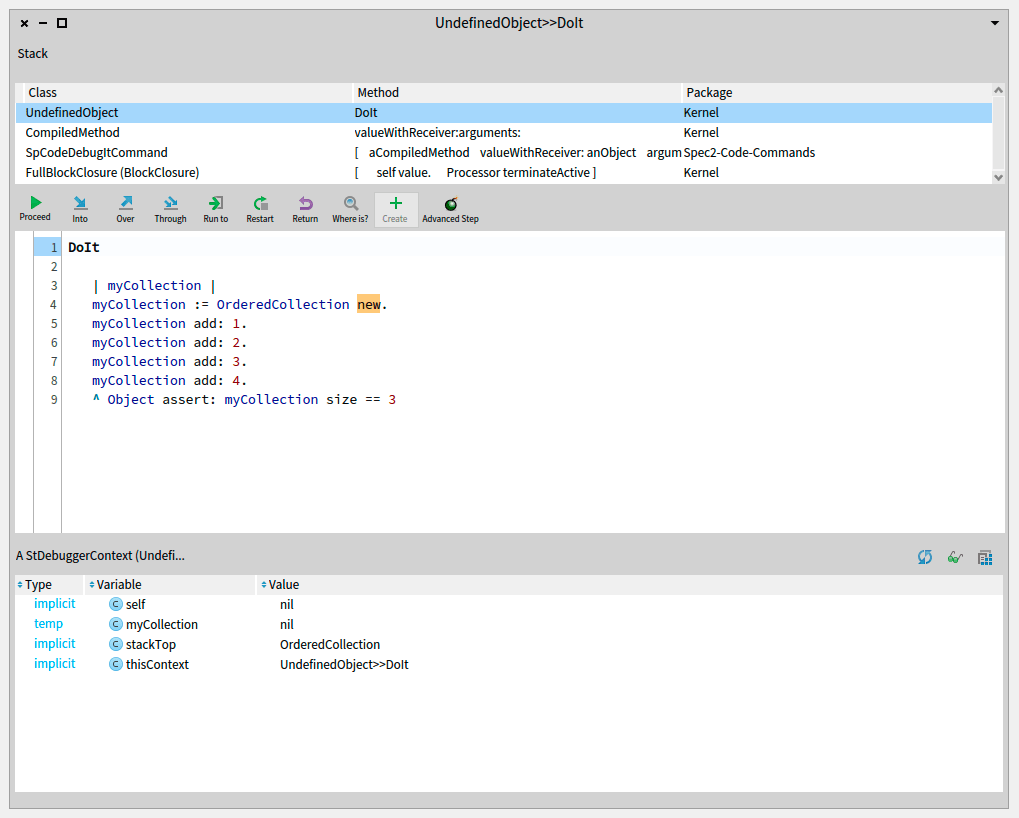
My first step was to understand how the correct case was working in build #162. I added a breakpoint in the closing of the code completion menu, tried to auto-complete something and clicked outside. The stack trace looked as follows:
We can see that the closing of the code completion menu happens when it loses the keyboard focus. Looking at the variables in the stack, the focus before the click was:
a RubEditingArea(583942144)
And the click is requesting focus on
a RubTextScrollPane(76486144)
But going a bit up in the stack, the code that produces the change in the focus is
A more insidious question: why does the NECMenuMorph receives the click? If I clicked outside of it!!! That is because the menu morph requests “mouse focus” when it is shown
The NECMenuMorph never becomes mouseFocus (I added a traceCr on mouse focus change, see below)
mouseFocus: aMorphOrNil
aMorphOrNil traceCr.
...
3. The code of show was changed (by myself) to not change the focus if no hand is available.
show
self resize.
self activeHand ifNotNil: [ :hand | hand newMouseFocus: self ].
self changed.
The problem was that the NECMenuMorph was trying to access the hand before being installed in the world! And the current hand depends on the world where we are installed. Otherwise, we need global state, which I was trying to minimize :)…
A solution
The solution I implemented was to call show once we are sure the morph is in the world.
This would mean that we can inline show in the openInWorld method and then remove the conditional. We can also argue that show is not morphic vocabulary…
In this post we have seen how we can chase a regression in Pharo by bisecting Pharo builds. Once the culprit build is identified, we can navigate from there to the pull request and thus the commits that cause the problem.
We have also shown how to compare two executions to understand the differences in behaviour, and finally how this was fixed in a real case.
Google Play Music (GPM) is a service proposed by Google to listen musics online (like Spotify, Deezer, …). Having a premium subscription, I can listen a lot of music by using the online service, but when I have no internet connection… I cannot 😦 . So I wanted to download the music ^^.
> This might be illegal, so, I used this situation to explain the process to use Pharo to download musics from GPM but you must not use this for real.
Approach
My idea is simple: if I can listen to musics from my computer, it means my computer has to download the music. I know that musics coming from GPM are in the mp3 format. So the process to download the music is simple:
Access the my GPM library.
For each music download the corresponding mp3 file.
Set the metadata of each music.
Access my GPM library
There is no official API for GPM service, however, the gmusicapi python project has been developed to create an unofficial API. This API allows us to access every element of our GPM library.
I’m not that good in Python, but I know it is possible to control python over Pharo. So I decided to use the PyBridge project of Vincent Aranega.
PyBridge allows us to use python language in Pharo. So, I’ll use it to load and use the unofficial GPM API.
Set up PyBridge
PyBridge is currently a work in progress and consequently requires a little set up. One needs to download the server project and the Pharo client project.
For the Pharo client project, it is super easy. I only need to download the project from GitHub and install the baseline:
Metacello new
baseline: 'PyBridge';
repository: 'github://aranega/pybridge/src';
load
For the Server project, the project is inside the python branch of the git repository. It requires pipenv to simply setup python vritual environments. So clone it in another folder and create a virtualenv by doing a simple:
$ pipenv install
Then, install the gmusicapi and run the server by executing the following commands:
Congratulations! You have correctly set up PyBridge to use the gmusicapi library!
Log in GPM
Before using the library, I need to log in inside GPM. To do so, I will use gmusicapi. The usage of the python library in Pharo is pretty forward as PyBridge exposes python objects in a Smalltalk fashion.
| mobileClient api |
"Access to the API class"
mobileClient := PyBridge load: #'gmusicapi::Mobileclient'.
"Create a new instance"
api := mobileClient new.
"Create authentification key"
api perform_oauth. "This step must be done only once by GPM account to get a oauth key."
"Login using oauth key"
api oauth_login: 'XXXXX' "XXXXX is my private key ^-^"
Nice! I have now a full access to the GPM API using PyBridge and Pharo.
Download mp3 files
GPM does not allow the users to download music. However, it is possible to ask for the audio stream in a mp3 format. I will use this to download the files ^-^.
In the following, I will present an example to download the album Hypnotize of System Of A Down. The album is in my GPM library so I can retrieve it in “my songs”.
To download the musics, I will access to all my musics libraries, select the music that belongs to the album, and then download the musics.
"access to all my songs"
library := api get_all_songs. "get_all_songs is part of the python library".
0 to: (library size - 1) do: [:index | "take care with index in python"
| music |
music := (library at: index)
((music at: #album) literalValue beginsWith: 'Hypnotize') "is the music at index part of the album?"
ifTrue: [
| fileRef |
fileRef := ('/home/user/music' asFileReference / ((music at: #title), '.mp3')).
fileRef binaryWriteStreamDo: [:mp3WriteStream |
(ZnEasy get: (api get_stream_url: (music at: #id))) writeOn: mp3WriteStream. "download the file"
].
]
]
I have now downloaded all the music of the album. To summarize:
Pharo asks for all songs to Python.
Then Pharo iterates on the Pyhton Map to select the correct musics.
It asks to Python the URL stream for a Music.
And it uses Zinc to download the music and creates the mp3 file.
Set the metadata
Our strategy works pretty well but the metadata of the mp3 files are not set. It can not be a problem but it is preferable when using a music manager (such as Clementine, Music Bee, Itunes, …). So, I will use VLC to set the metadata of our files. It is possible to use VLC through Pharo using the Pharo-LibVLC project.
Set Up Pharo LibVLC
Installing the FFI binding of VLC for Pharo is easy. You need to: (1) install VLC, and (2) install Pharo-LibVLC.
Metacello new
baseline: 'VLC';
repository: 'github://badetitou/Pharo-LibVLC';
load.
Then, it is possible to use VLC in Pharo after initializing it.
Inside the previous script, I insert the code to set metadata using VLC. First, I create a reference to the mp3 file for VLC, then I set the metadata using VLC API.
...
| media |
media := vlc createMediaFromPath: fileRef fullName. "create mp3 reference for VLC"
media setMeta: VLCMetaT libvlc_meta_Album with: (music at: #album) literalValue asString.
media setMeta: VLCMetaT libvlc_meta_Title with: (music at: #title) literalValue asString.
media saveMeta.
media release.
...
In the example, I only set “album” and “title” attribute but it is possible to set more metadata.
Conclusion
I have used Zinc, VLC, and Python with a Python library to download musics for Google Play Music service. It shows how easy it is to use Pharo with other programming languages and I hope it will help you to create many super cool projects.
> I REMIND YOU THAT THIS WORK MIGHT NOT LEGAL SO CONSIDER IT ONLY AS AN EXAMPLE!
This is a brief post on how to load the sound package, enable it and play some sound samples in Pharo 9.0. For Pharo 9.0, we fixed the sound support by refactoring and using SDL2 for enqueuing the playback of sound samples. The current version only supports sound playback, but it does not support yet sound recording from a microphone.
Downloading a clean Pharo 9 image and VM
Some users have reported on following these instructions on older of Pharo. In case a weird problem is obtained such as “Failed to open /dev/dsp”, we recommend to download the latest Pharo 9 image and headless virtual machine. This image and VM can be downloaded through the Pharo Launcher, manually through the files server in the Pharo website, or by executing the following Zeroconf bash script in Linux or in OS X:
The first step required to be able to play sound in Pharo 9.0 is to load the Sound package. The Sound package is not included by default in the main Pharo image, so it has be loaded explicitly. The following Metacello script can be used for loading the Sound by doing it in a Playground:
Metacello new baseline: 'Sound'; repository: 'github://pharo-contributions/Sound'; load
Setting for enabling Sound
Loading the sound package is not enough to be able to play sound in Pharo. In addition to loading this package, it is required to enable sound playback under the Settings browser. After the Sound package is loaded, under the Appearance category, a setting named “Sound” appears with a checkbox that needs to be enabled to activate sound playback.
Examples for playing Sound samples
The Sound package bundles several software based synthesizers, so it is not required to load explicit wave (.WAV) files in order to play samples and music for testing it. The following is an example script for playing major scale with an electric bass patch that is generated through FM synthesis:
(FMSound lowMajorScaleOn: FMSound bass1) play
Since we are inheriting this package from older versions of Pharo, we do not comprehend yet all of the features for sound and music synthesis that are provided by this package. However, we recommend to look on the existing instrument examples that are present in the class side of the AbstractSound and FMSound classes.
Wave samples (.wav) from disk can be loaded and played through the SampledSound class. For example, if we have a sound sample in a file named test.wav, in the same folder as the image, we can load it and play it with the following script:
(SampledSound fromWaveFileNamed: 'test.wav') play
The most complicated and spectacular example that is bundled in the Sound package is a playback of the Bach Little Fugue with multiple stereophonic voices. This example can be started with the following short script in a Playground:
AbstractSound stereoBachFugue play
If you want to
If you want to contribute…
The sound package is hosted on http://github.com and you can really help us to improve it.
Metacello new
baseline: 'Sound';
repository: 'github://pharo-contributions/Sound';
load