This is the fourth entry of the series about implementing full-text search indexes in Pharo. All started with the first entry Implementing Indexes – A Simple Index, where we present the need for having indexes in large images. Then, we have the second entry is Implementing Indexes – Who uses all my memory, where we analysed the first version and the problems it has. And then, the third entry Implementing Indexes – Compressing the Trie where we show some improvements in the Trie implementation.

This fourth and final entry analyses the remaining problem in the implementation: the space taken by the identity dictionary.
Remember the Problem
When we check the result of analysing the memory impact of our solution, as we have seen in the previous blog entries. We have the following table:
| Class name | # Instances | Memory (Bytes) | Memory(%) |
| Array | 159,603 | 7,696,272 | 36.46% |
| CTTrieNode | 159,603 | 5,107,296 | 24.20% |
| IdentityDictionary | 159,603 | 3,830,472 | 18.15% |
| Association | 159,602 | 3,830,448 | 18.15% |
| ByteString | 9,244 | 349,968 | 1.66% |
| ByteSymbol | 9,244 | 294,008 | 1.39% |
| CTTrie | 1 | 16 | 0.00% |
| UndefinedObject | 1 | 16 | 0.00% |
| SmallInteger | 90 | 0 | 0.00% |
| Character | 64 | 0 | 0.00% |
| Total | 21,108,496 | 100.00% |
We can see that the main memory is taken by 4 classes (Array, CTTrieNode, IdentityDictionary and Association). Also, it is clear that we have a relation between the number of instances of these classes and the amount of nodes in the Trie.
If we check the raw structure of our nodes we have something like this:

We can see that each node has an IdentityDictionary with a Character as key and a CTTrieNode. This creates the structure of nodes that we have in the Trie. From this, we can explain the number of instances of IdentityDictionary… but where are all the arrays and associations? They are taking 55% of the memory, so we have to find them.
If we continue exploring, we can see how IdentityDictionary is implemented in Pharo.
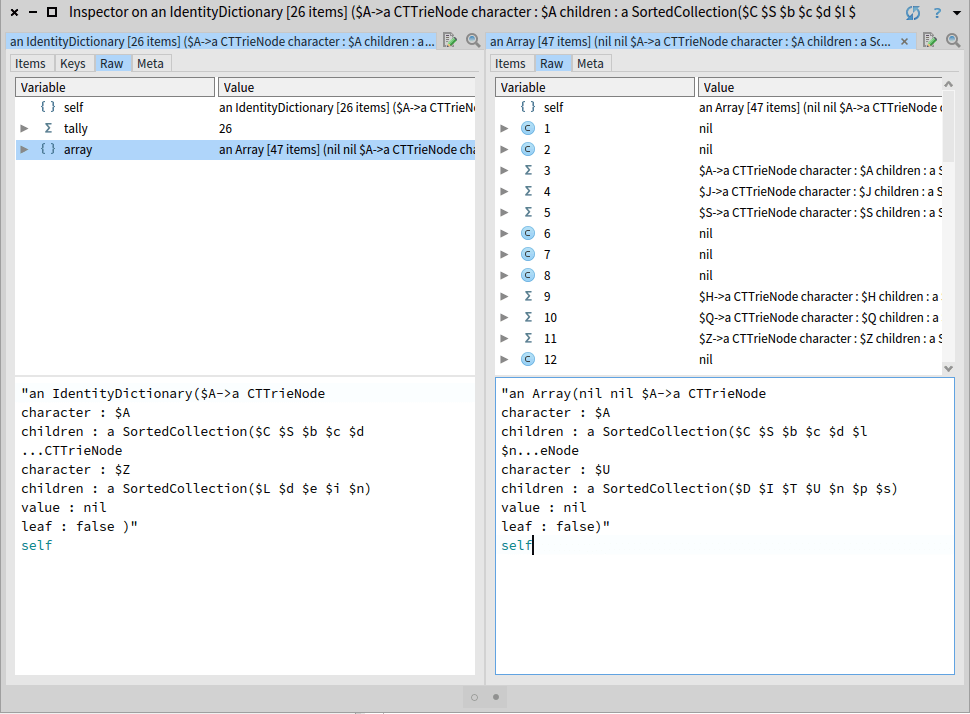
Dictionaries in Pharo are implemented by using an internal array. This array contains Associations. Each association has a key and a value. Those are the keys and values of the dictionary. We can see this when we continue inspecting the objects.
Also, the associations are stored in the array. The associations are not in the array in sequential positions, there are holes in the middle. Each association is stored in the position that is associated with the hash of the key. So, it is easier to look for the association when accessing by the key (remember, that the Dictionaries are optimized to access by the key). You can check the comments in classes like Dictionary and HashedCollection to understand this behavior.
Finally, to improve the speed of adding new elements, the arrays have always free positions.
This design is great to provide a fast access to the information, to speed up the access and the insertion of new elements. However, as always, we are trading speed for space. In our specific case, we want to improve the memory footprint.
Basically we need to address:
- Remove the need to have an IdentityDictionary and an Array. Can we have a single instance?
- Remove the use of associations
- Remove the empty slots in the array.
- Doing all the previous without destroying the access performance 🙂
A compromise solution
When solving problems in the real world we need to make trade-offs. Our solution is slower, but it takes less space. So, we need to balance these two problems.
We have solved the problem by implementing the dictionary using a single array without associations. The TrieNode will store each pair key-value directly in a compact array (the array is created every time with only the occupied space). Each key-value pair is stored in the array in sequential positions, and in the order they were added to the node.
For example if we have the pairs key -> value, added in that order:
$C -> nodeC. $A -> nodeA. $B -> nodeB.
The array will contain them as:
{$C. nodeC. $A. nodeA. $B. nodeB}
So, in the optimized version the nodes have this structure:

The keys are stored in the odd positions of the array, and the values in the even positions. Each key is next to its value. So, it is still possible to access the value from the key and the key from the value, but it requires to traverse the whole array.
Benefits of the solution
If we analyse the impact of the new solution, we can see that the memory footprint has been reduced to a less of a tenth of the original solution. This is the combination of the optimization of the last blog post and the one done here.
| Class name | # Instances | Memory (Bytes) | Memory(%) |
| ByteString | 31343 | 757,576 | 37.16% |
| CTOptimizedTrieNode | 22102 | 530,448 | 26.02% |
| Array | 12859 | 456,496 | 22.39% |
| ByteSymbol | 9244 | 294,008 | 14.42% |
| CTOptimizedTrie | 1 | 16 | 0.00% |
| UndefinedObject | 1 | 16 | 0.00% |
| SmallInteger | 64 | 0 | 0.00% |
| Total | 2,038,560 | 100.00% |
A clear improvement is the size of the arrays. Not only we have less arrays (because we have less nodes, thanks to the improvement done in the previous blog post) but also each array occupies less space, because they have less empty slots.
Problems of the Solution
As we have said before, there is no perfect general solution, but correct solutions for specific situations. In this case, we have put the accent in the memory impact, but it has the following drawbacks.
- Our solution implements a custom data structure, so we needed to implement it from scratch. This introduces possible points where we have bugs and problems that we have not seen.
- We are not taking advantage of the implementation of Dictionary in the image, so we are duplicating code.
- We are penalizing the creation of new nodes, as the array has to be copied into a larger one.
- The access to this data structure is linear, so we are penalizing the access time also. The complete array has to be traversed to access or check if an element is there.
- We have to carefully crafted the code to access the data structure not to penalize the execution time more than we can allow. This code is performance sensitive and any change to it has to be carefully tested and measure; benchmarks and profiling are good friends.
These drawbacks are not important in our current situation, but can make this optimization technique unusable.
Conclusion
In this Trie-logy of blog entries we have presented a real problem that we have seen during the development of Pharo. The intention of this serie is to not only present a solution but to present the tools and the engineering process we did to arrive to the solution. The process and the tools are more valuable than this specific solution, as the solution is only valid in our context. So, we consider a good practice that can be useful to other developers in completely different situations.
